numpy.random.Generator.f#
方法
- random.Generator.f(dfnum, dfden, size=None)#
從 F 分佈中抽取樣本。
樣本是從具有指定參數 dfnum (分子自由度) 和 dfden (分母自由度) 的 F 分佈中抽取的,其中兩個參數都必須大於零。
F 分佈(也稱為費雪分佈)的隨機變數是一種連續機率分佈,出現在 ANOVA 檢定中,並且是兩個卡方變數的比率。
- 參數:
- dfnumfloat 或 float 的類陣列
分子自由度,必須 > 0。
- dfdenfloat 或 float 的類陣列
分母自由度,必須 > 0。
- sizeint 或 int 元組,選填
輸出形狀。如果給定的形狀是例如
(m, n, k),則會抽取m * n * k個樣本。如果 size 為None(預設值),如果dfnum和dfden都是純量,則會傳回單一值。否則,會抽取np.broadcast(dfnum, dfden).size個樣本。
- 傳回值:
- outndarray 或 純量
從參數化的費雪分佈中抽取的樣本。
另請參閱
scipy.stats.f機率密度函數、分佈或累積密度函數等等。
註解
F 統計量用於比較組內變異數和組間變異數。分佈的計算取決於抽樣,因此它是問題中各自自由度的函數。dfnum 變數是樣本數減一,即組間自由度,而 dfden 是組內自由度,即每組樣本數的總和減去組數。
參考文獻
[1]Glantz, Stanton A. “Primer of Biostatistics.”, McGraw-Hill, Fifth Edition, 2002.
[2]Wikipedia, “F-distribution”, https://en.wikipedia.org/wiki/F-distribution
範例
Glantz[1] 第 47-40 頁的範例
兩組,糖尿病患者的子女 (25 人) 和非糖尿病患者的子女 (25 名對照組)。測量了空腹血糖,病例組的平均值為 86.1,對照組的平均值為 82.2。標準差分別為 2.09 和 2.49。這些數據是否與父母糖尿病狀況不影響其子女血糖水平的虛無假設一致?從數據計算出的 F 統計量值為 36.01。
從分佈中抽取樣本
>>> dfnum = 1. # between group degrees of freedom >>> dfden = 48. # within groups degrees of freedom >>> rng = np.random.default_rng() >>> s = rng.f(dfnum, dfden, 1000)
樣本前 1% 的下限是
>>> np.sort(s)[-10] 7.61988120985 # random
因此,F 統計量超過 7.62 的機率約為 1%,測量值為 36,因此在 1% 水準下拒絕虛無假設。
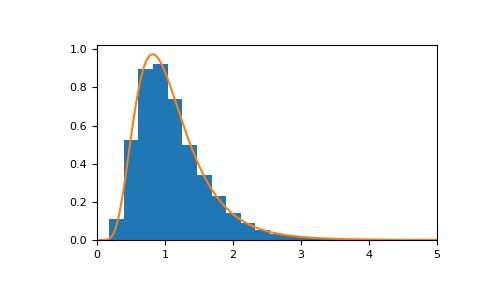
n = 20和m = 20的對應機率密度函數為>>> import matplotlib.pyplot as plt >>> from scipy import stats >>> dfnum, dfden, size = 20, 20, 10000 >>> s = rng.f(dfnum=dfnum, dfden=dfden, size=size) >>> bins, density, _ = plt.hist(s, 30, density=True) >>> x = np.linspace(0, 5, 1000) >>> plt.plot(x, stats.f.pdf(x, dfnum, dfden)) >>> plt.xlim([0, 5]) >>> plt.show()