
n 維陣列上的線性代數#
先備條件#
在閱讀本教學文件之前,您應該對 Python 有一些了解。如果您想複習一下記憶,請看看 Python 教學文件。
如果您想能夠執行本教學文件中的範例,您也應該在您的電腦上安裝 matplotlib 和 SciPy。
學習者概況#
本教學文件適用於對 NumPy 中的線性代數和陣列有基本了解,並想了解 n 維 (\(n>=2\)) 陣列如何表示和操作的人。特別是,如果您不知道如何將常用函數應用於 n 維陣列(不使用 for 迴圈),或者如果您想了解 n 維陣列的軸和形狀屬性,本教學文件可能會有所幫助。
學習目標#
完成本教學文件後,您應該能夠:
理解 NumPy 中一維、二維和 n 維陣列之間的差異;
理解如何在不使用 for 迴圈的情況下,將一些線性代數運算應用於 n 維陣列;
理解 n 維陣列的軸和形狀屬性。
內容#
在本教學文件中,我們將使用線性代數中的 矩陣分解(奇異值分解)來產生影像的壓縮近似值。我們將使用來自 scipy.datasets 模組的 face 影像
# TODO: Rm try-except with scipy 1.10 is the minimum supported version
try:
from scipy.datasets import face
except ImportError: # Data was in scipy.misc prior to scipy v1.10
from scipy.misc import face
img = face()
Downloading file 'face.dat' from 'https://raw.githubusercontent.com/scipy/dataset-face/main/face.dat' to '/home/circleci/.cache/scipy-data'.
注意:如果您願意,您可以使用自己的影像來完成本教學文件。為了將您的影像轉換為可操作的 NumPy 陣列,您可以使用來自 matplotlib.pyplot 子模組的 imread 函數。或者,您可以使用來自 imageio 函式庫的 imageio.imread 函數。請注意,如果您使用自己的影像,您可能需要調整以下步驟。有關影像在轉換為 NumPy 陣列時如何處理的更多資訊,請參閱來自 scikit-image 文件中的 NumPy 影像速成課程。
現在,img 是一個 NumPy 陣列,正如我們在使用 type 函數時所見
type(img)
numpy.ndarray
我們可以使用 matplotlib.pyplot.imshow 函數和特殊的 iPython 命令 %matplotlib inline 來顯示內嵌繪圖
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(img)
plt.show()

形狀、軸與陣列屬性#
請注意,在線性代數中,向量的維度是指陣列中條目的數量。在 NumPy 中,它反而定義了軸的數量。例如,一維陣列是一個向量,例如 [1, 2, 3],二維陣列是一個矩陣,依此類推。
首先,讓我們檢查陣列中資料的形狀。由於此影像為二維(影像中的像素形成一個矩形),我們可能會期望一個二維陣列來表示它(一個矩陣)。但是,使用此 NumPy 陣列的 shape 屬性給我們一個不同的結果
img.shape
(768, 1024, 3)
輸出是一個具有三個元素的 元組,這表示這是一個三維陣列。事實上,由於這是一個彩色影像,而且我們使用了 imread 函數來讀取它,因此資料被組織成三個二維陣列,表示顏色通道(在本例中為紅色、綠色和藍色 - RGB)。您可以從上面的形狀中看到這一點:它表示我們有一個由 3 個矩陣組成的陣列,每個矩陣的形狀為 768x1024。
此外,使用此陣列的 ndim 屬性,我們可以知道
img.ndim
3
NumPy 將每個維度稱為軸。由於 imread 的運作方式,第三個軸中的第一個索引是我們影像的紅色像素資料。我們可以透過使用以下語法來存取它
img[:, :, 0]
array([[121, 138, 153, ..., 119, 131, 139],
[ 89, 110, 130, ..., 118, 134, 146],
[ 73, 94, 115, ..., 117, 133, 144],
...,
[ 87, 94, 107, ..., 120, 119, 119],
[ 85, 95, 112, ..., 121, 120, 120],
[ 85, 97, 111, ..., 120, 119, 118]], dtype=uint8)
從上面的輸出中,我們可以看到 img[:, :, 0] 中的每個值都是介於 0 到 255 之間的整數值,表示每個對應影像像素中的紅色程度(請記住,如果您使用自己的影像而不是 scipy.datasets.face,這可能會有所不同)。
正如預期的,這是一個 768x1024 矩陣
img[:, :, 0].shape
(768, 1024)
由於我們將對此資料執行線性代數運算,因此在矩陣的每個條目中使用介於 0 和 1 之間的實數來表示 RGB 值可能更有趣。我們可以透過設定來做到這一點
img_array = img / 255
這個將陣列除以純量的運算之所以有效,是因為 NumPy 的 廣播規則。(請注意,在真實世界的應用程式中,最好使用例如來自 scikit-image 的 img_as_float 實用函數)。
您可以透過執行一些測試來檢查以上是否有效;例如,查詢此陣列的最大值和最小值
img_array.max(), img_array.min()
(np.float64(1.0), np.float64(0.0))
或檢查陣列中資料的類型
img_array.dtype
dtype('float64')
請注意,我們可以使用切片語法將每個顏色通道分配給一個單獨的矩陣
red_array = img_array[:, :, 0]
green_array = img_array[:, :, 1]
blue_array = img_array[:, :, 2]
軸上的運算#
可以使用線性代數中的方法來近似現有的資料集。在這裡,我們將使用 SVD(奇異值分解) 來嘗試重建一個影像,該影像使用的奇異值資訊比原始影像少,同時仍保留其某些特徵。
注意:我們將使用 NumPy 的線性代數模組 numpy.linalg 來執行本教學文件中的運算。此模組中的大多數線性代數函數也可以在 scipy.linalg 中找到,並鼓勵使用者在真實世界的應用程式中使用 scipy 模組。但是,scipy.linalg 模組中的某些函數(例如 SVD 函數)僅支援 2D 陣列。有關更多資訊,請查看 scipy.linalg 頁面。
若要繼續,請從 NumPy 匯入線性代數子模組
from numpy import linalg
為了從給定的矩陣中提取資訊,我們可以使用 SVD 來獲得 3 個陣列,這些陣列可以相乘以獲得原始矩陣。從線性代數的理論來看,給定一個矩陣 \(A\),可以計算以下乘積
其中 \(U\) 和 \(V^T\) 是方形的,而 \(\Sigma\) 的大小與 \(A\) 相同。\(\Sigma\) 是一個對角矩陣,其中包含 \(A\) 的 奇異值,從最大到最小排列。這些值始終為非負數,可以用作表示矩陣 \(A\) 所表示的某些特徵的「重要性」指標。
讓我們看看這在實務中如何運作,首先只使用一個矩陣。請注意,根據 色彩學,如果我們應用以下公式,則可以獲得相當合理的彩色影像灰階版本
其中 \(Y\) 是表示灰階影像的陣列,而 \(R\)、\(G\) 和 \(B\) 是我們最初擁有的紅色、綠色和藍色通道陣列。請注意,我們可以將 @ 運算子(NumPy 陣列的矩陣乘法運算子,請參閱 numpy.matmul)用於此操作
img_gray = img_array @ [0.2126, 0.7152, 0.0722]
現在,img_gray 的形狀為
img_gray.shape
(768, 1024)
為了查看這在我們的影像中是否有意義,我們應該使用來自 matplotlib 的色表,該色表對應於我們希望在影像中看到的顏色(否則,matplotlib 將預設為不對應於真實資料的色表)。
在我們的例子中,我們正在近似影像的灰階部分,因此我們將使用色表 gray
plt.imshow(img_gray, cmap="gray")
plt.show()

現在,將 linalg.svd 函數應用於此矩陣,我們獲得以下分解
U, s, Vt = linalg.svd(img_gray)
注意 如果您使用的是自己的影像,則此命令可能需要一段時間才能執行,具體取決於您的影像大小和硬體。別擔心,這是正常的!SVD 可能是一個非常密集的計算。
讓我們檢查一下這是否是我們預期的
U.shape, s.shape, Vt.shape
((768, 768), (768,), (1024, 1024))
請注意,s 具有特定的形狀:它只有一個維度。這表示某些期望 2d 陣列的線性代數函數可能無法運作。例如,從理論上講,人們可能會期望 s 和 Vt 與乘法相容。但是,這是不正確的,因為 s 沒有第二個軸。執行
s @ Vt
會導致 ValueError。發生這種情況是因為在這種情況下,對於 s 使用一維陣列在實務上比建構具有相同資料的對角矩陣更經濟。為了重建原始矩陣,我們可以重建對角矩陣 \(\Sigma\),其對角線中包含 s 的元素,並具有適合乘法的維度:在我們的例子中,\(\Sigma\) 應該是 768x1024,因為 U 是 768x768,而 Vt 是 1024x1024。為了將奇異值新增到 Sigma 的對角線,我們將使用 NumPy 中的 fill_diagonal 函數
import numpy as np
Sigma = np.zeros((U.shape[1], Vt.shape[0]))
np.fill_diagonal(Sigma, s)
現在,我們想檢查重建的 U @ Sigma @ Vt 是否接近原始的 img_gray 矩陣。
近似#
linalg 模組包含一個 norm 函數,該函數計算 NumPy 陣列中表示的向量或矩陣的範數。例如,從上面的 SVD 說明中,我們期望 img_gray 與重建的 SVD 乘積之間的差異範數很小。正如預期的那樣,您應該會看到類似
linalg.norm(img_gray - U @ Sigma @ Vt)
np.float64(1.43712046073728e-12)
(此運算的實際結果可能會因您的架構和線性代數設定而異。無論如何,您應該會看到一個很小的數字。)
我們也可以使用 numpy.allclose 函數來確保重建的乘積實際上接近我們的原始矩陣(兩個陣列之間的差異很小)
np.allclose(img_gray, U @ Sigma @ Vt)
True
若要查看近似值是否合理,我們可以檢查 s 中的值
plt.plot(s)
plt.show()
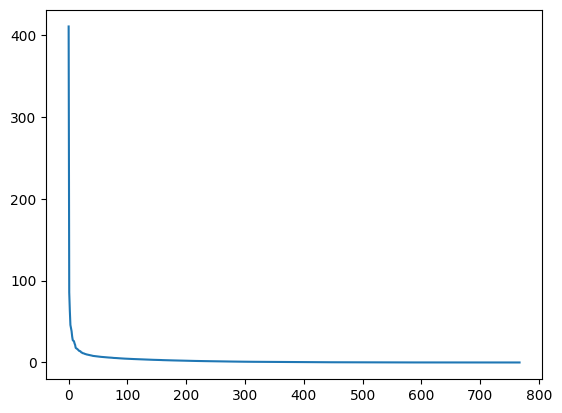
在圖表中,我們可以看到,儘管我們在 s 中有 768 個奇異值,但大多數奇異值(在第 150 個條目左右之後)都非常小。因此,僅使用與前(例如,50 個)奇異值相關的資訊來建構影像的更經濟的近似值可能是有意義的。
這個想法是將 Sigma(與 s 中的奇異值相同)中除前 k 個奇異值以外的所有奇異值視為零,保持 U 和 Vt 不變,並計算這些矩陣的乘積作為近似值。
例如,如果我們選擇
k = 10
我們可以透過執行以下操作來建構近似值
approx = U @ Sigma[:, :k] @ Vt[:k, :]
請注意,我們必須僅使用 Vt 的前 k 列,因為所有其他列都將乘以與我們從此近似值中消除的奇異值對應的零。
plt.imshow(approx, cmap="gray")
plt.show()

現在,您可以繼續並使用 k 的其他值重複此實驗,並且您的每個實驗都應根據您選擇的值為您提供稍微更好(或更差)的影像。
應用於所有顏色#
現在我們想對所有三種顏色執行相同的操作。我們的第一個直覺可能是對每個顏色矩陣單獨重複我們上面執行的相同操作。但是,NumPy 的廣播會為我們處理這個問題。
如果我們的陣列具有兩個以上的維度,則 SVD 可以一次應用於所有軸。但是,NumPy 中的線性代數函數期望看到形狀為 (n, M, N) 的陣列,其中第一個軸 n 表示堆疊中 MxN 矩陣的數量。
在我們的例子中,
img_array.shape
(768, 1024, 3)
因此我們需要置換此陣列上的軸,以獲得類似 (3, 768, 1024) 的形狀。幸運的是,numpy.transpose 函數可以為我們做到這一點
np.transpose(x, axes=(i, j, k))
表示軸將被重新排序,使得轉置陣列的最終形狀將根據索引 (i, j, k) 重新排序。
讓我們看看這對我們的陣列有何影響
img_array_transposed = np.transpose(img_array, (2, 0, 1))
img_array_transposed.shape
(3, 768, 1024)
現在我們已準備好應用 SVD
U, s, Vt = linalg.svd(img_array_transposed)
最後,為了獲得完整的近似影像,我們需要將這些矩陣重新組裝到近似值中。現在,請注意
U.shape, s.shape, Vt.shape
((3, 768, 768), (3, 768), (3, 1024, 1024))
為了建構最終的近似矩陣,我們必須了解跨不同軸的乘法如何運作。
n 維陣列的乘積#
如果您之前僅使用過 NumPy 中的一維或二維陣列,您可能會互換使用 numpy.dot 和 numpy.matmul(或 @ 運算子)。但是,對於 n 維陣列,它們的運作方式非常不同。有關更多詳細資訊,請查看關於 numpy.matmul 的文件。
現在,為了建構我們的近似值,我們首先需要確保我們的奇異值已準備好進行乘法,因此我們以與之前類似的方式建構我們的 Sigma 矩陣。Sigma 陣列的維度必須為 (3, 768, 1024)。為了將奇異值新增到 Sigma 的對角線,我們將再次使用 fill_diagonal 函數,使用 s 中的 3 列中的每一列作為 Sigma 中 3 個矩陣中的每一個的對角線
Sigma = np.zeros((3, 768, 1024))
for j in range(3):
np.fill_diagonal(Sigma[j, :, :], s[j, :])
現在,如果我們希望重建完整的 SVD(沒有近似值),我們可以執行
reconstructed = U @ Sigma @ Vt
請注意
reconstructed.shape
(3, 768, 1024)
重建的影像應與原始影像無法區分,但重建產生的浮點錯誤除外。回想一下,我們的原始影像由範圍 [0., 1.] 中的浮點值組成。重建產生的浮點錯誤累積可能會導致值稍微超出此原始範圍
reconstructed.min(), reconstructed.max()
(np.float64(-5.558487697898684e-15), np.float64(1.0000000000000053))
由於 imshow 期望值在該範圍內,因此我們可以使用 clip 來去除浮點錯誤
reconstructed = np.clip(reconstructed, 0, 1)
plt.imshow(np.transpose(reconstructed, (1, 2, 0)))
plt.show()

事實上,imshow 在底層執行此剪裁,因此如果您跳過先前程式碼儲存格中的第一行,您可能會看到警告訊息,指出 "Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers)."
現在,為了進行近似,我們必須僅為每個顏色通道選擇前 k 個奇異值。這可以使用以下語法完成
approx_img = U @ Sigma[..., :k] @ Vt[..., :k, :]
您可以看到,我們僅為 Sigma 選擇了最後一個軸的前 k 個元件(這表示我們僅使用了堆疊中三個矩陣中的每一個的前 k 列),並且我們僅在 Vt 的倒數第二個軸中選擇了前 k 個元件(這表示我們從堆疊 Vt 中的每個矩陣中選擇了前 k 列和所有行)。如果您不熟悉省略號語法,它是其他軸的預留位置。有關更多詳細資訊,請參閱關於 索引 的文件。
現在,
approx_img.shape
(3, 768, 1024)
這不是顯示影像的正確形狀。最後,將軸重新排序回我們原始的 (768, 1024, 3) 形狀,我們可以查看我們的近似值
plt.imshow(np.transpose(approx_img, (1, 2, 0)))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-0.135671314724608..1.079453607915587].
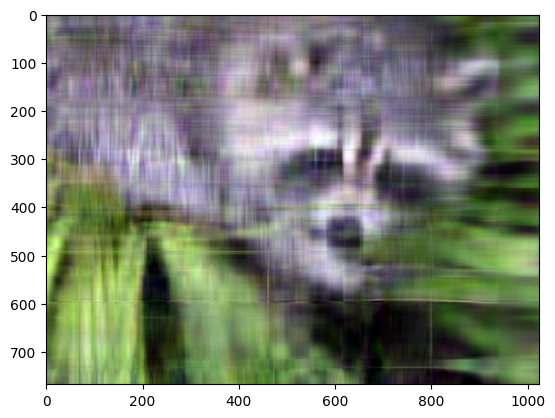
即使影像不夠清晰,但使用少量 k 奇異值(與原始的 768 個值集相比),我們也可以從此影像中恢復許多顯著特徵。
結語#
當然,這不是近似影像的最佳方法。但是,線性代數中實際上存在一個結果,指出我們在上面建構的近似值是我們可以獲得的最接近原始矩陣的近似值,就差異的範數而言。有關更多資訊,請參閱 G. H. Golub 和 C. F. Van Loan, Matrix Computations, Baltimore, MD, Johns Hopkins University Press, 1985。