
分析印度德里封鎖對空氣品質的影響#

您將會做什麼#
計算空氣品質指標 (AQI) 並對其執行配對學生 t 檢定。
您將會學到什麼#
您將學習移動平均的概念
您將學習如何計算空氣品質指標 (AQI)
您將學習如何執行配對學生 t 檢定並找出
t和p值您將學習如何解釋這些值
您需要的東西#
您的環境中已安裝 SciPy
對統計術語的基本理解,例如母體、樣本、平均值、標準差等。
空氣污染的問題#
空氣污染是我們面臨最顯著的污染類型之一,它對我們的日常生活產生直接影響。 COVID-19 疫情導致世界各地實施封鎖;為研究人類活動(或缺乏人類活動)對空氣污染的影響提供了難得的機會。在本教學中,我們將研究德里的空氣品質,德里是受空氣污染影響最嚴重的城市之一,研究 2020 年 3 月至 6 月封鎖前後的空氣品質。為此,我們將首先根據收集的污染物測量值計算每小時的空氣品質指標。接下來,我們將對這些指標進行抽樣,並對它們執行配對學生 t 檢定。這將在統計上向我們展示空氣品質因封鎖而改善,從而支持我們的直覺。
讓我們從將必要的程式庫匯入到我們的環境中開始。
import numpy as np
from numpy.random import default_rng
from scipy import stats
建立資料集#
我們將使用印度空氣品質數據資料集的精簡版本。此資料集包含印度多個城市各站點每小時和每日的空氣品質數據和 AQI(空氣品質指標)。本教學提供的精簡版本包含 2019 年 5 月 31 日至 2020 年 6 月 30 日德里每小時的污染物測量值。它具有空氣品質指標計算所需的標準污染物以及其他一些重要污染物的測量值:懸浮微粒(PM 2.5 和 PM 10)、二氧化氮 (NO2)、氨氣 (NH3)、二氧化硫 (SO2)、一氧化碳 (CO)、臭氧 (O3)、氮氧化物 (NOx)、一氧化氮 (NO)、苯、甲苯和二甲苯。
讓我們印出前幾列,以了解我們的資料集。
! head air-quality-data.csv
Datetime,PM2.5,PM10,NO2,NH3,SO2,CO,O3,NOx,NO,Benzene,Toluene,Xylene
2019-05-31 00:00:00,103.26,305.46,94.71,31.43,30.16,3.0,18.06,178.31,152.73,13.65,83.47,2.54
2019-05-31 01:00:00,104.47,309.14,74.66,34.08,27.02,1.69,18.65,106.5,79.98,11.35,76.79,2.91
2019-05-31 02:00:00,90.0,314.02,48.11,32.6,18.12,0.83,28.27,48.45,25.27,5.66,32.91,1.59
2019-05-31 03:00:00,78.01,356.14,45.45,30.21,16.78,0.79,27.47,44.22,21.5,3.6,21.41,0.78
2019-05-31 04:00:00,80.19,372.9,45.23,28.68,16.41,0.76,26.92,44.06,22.15,4.5,23.39,0.62
2019-05-31 05:00:00,83.59,389.97,39.49,27.71,17.42,0.76,28.71,39.33,21.04,3.25,23.59,0.56
2019-05-31 06:00:00,79.04,371.64,39.61,26.87,16.91,0.84,29.26,43.11,24.37,3.12,15.27,0.46
2019-05-31 07:00:00,77.32,361.88,42.63,27.26,17.86,0.96,27.07,48.22,28.81,3.32,14.42,0.41
2019-05-31 08:00:00,84.3,377.77,42.49,28.41,20.19,0.98,33.05,48.22,27.76,3.4,14.53,0.4
就本教學而言,我們僅關注計算 AQI 所需的標準污染物,即 PM 2.5、PM 10、NO2、NH3、SO2、CO 和 O3。因此,我們將僅使用 np.loadtxt 匯入這些特定列。然後,我們將切片並建立兩個集合:包含 PM 2.5、PM 10、NO2、NH3 和 SO2 的 pollutants_A,以及包含 CO 和 O3 的 pollutants_B。這兩個集合的處理方式會略有不同,我們稍後會看到。
pollutant_data = np.loadtxt("air-quality-data.csv", dtype=float, delimiter=",",
skiprows=1, usecols=range(1, 8))
pollutants_A = pollutant_data[:, 0:5]
pollutants_B = pollutant_data[:, 5:]
print(pollutants_A.shape)
print(pollutants_B.shape)
(9528, 5)
(9528, 2)
我們的資料集可能包含遺失值,以 NaN 表示,因此讓我們使用 np.isfinite 快速檢查一下。
np.all(np.isfinite(pollutant_data))
np.True_
有了這個,我們就成功匯入了資料並檢查了資料的完整性。讓我們繼續進行 AQI 計算!
計算空氣品質指標#
我們將使用方法計算 AQI,該方法由印度中央污染控制委員會採用。總結步驟
收集標準污染物的 24 小時平均濃度值;CO 和 O3 的情況為 8 小時。
使用以下公式計算這些污染物的子指標
\[ Ip = \dfrac{\text{IHi – ILo}}{\text{BPHi – BPLo}}\cdot{\text{Cp – BPLo}} + \text{ILo} \]其中,
Ip= 污染物p的子指標
Cp= 污染物p的平均濃度
BPHi= 濃度斷點,即大於或等於Cp
BPLo= 濃度斷點,即小於或等於Cp
IHi= 對應於BPHi的 AQI 值
ILo= 對應於BPLo的 AQI 值任何給定時間的最大子指標就是空氣品質指標。
空氣品質指標是借助下圖所示的斷點範圍計算得出的。
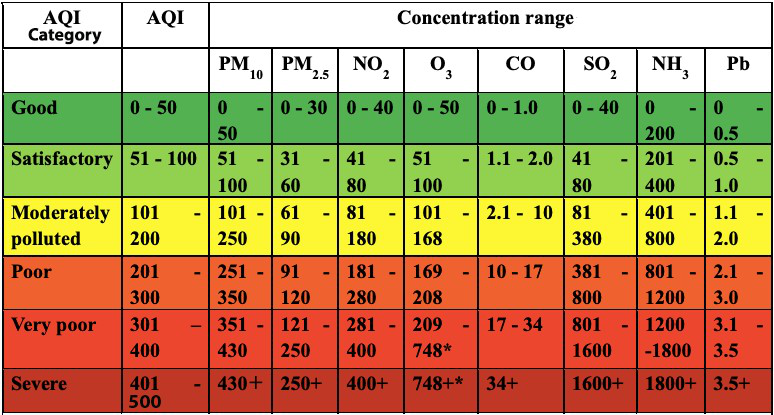
讓我們建立兩個陣列來儲存 AQI 範圍和斷點,以便稍後將它們用於我們的計算。
AQI = np.array([0, 51, 101, 201, 301, 401, 501])
breakpoints = {
'PM2.5': np.array([0, 31, 61, 91, 121, 251]),
'PM10': np.array([0, 51, 101, 251, 351, 431]),
'NO2': np.array([0, 41, 81, 181, 281, 401]),
'NH3': np.array([0, 201, 401, 801, 1201, 1801]),
'SO2': np.array([0, 41, 81, 381, 801, 1601]),
'CO': np.array([0, 1.1, 2.1, 10.1, 17.1, 35]),
'O3': np.array([0, 51, 101, 169, 209, 749])
}
移動平均#
第一步,我們必須計算 pollutants_A 在 24 小時視窗內的移動平均值,以及 pollutants_B 在 8 小時視窗內的移動平均值。我們將使用 np.cumsum 和切片索引編寫一個簡單的函數 moving_mean 來實現此目的。
為了確保兩個集合的長度相同,我們將根據 pollutants_A_24hr_avg 的長度截斷 pollutants_B_8hr_avg。這也將確保我們在相同的時間段內擁有所有污染物的濃度。
def moving_mean(a, n):
ret = np.cumsum(a, dtype=float, axis=0)
ret[n:] = ret[n:] - ret[:-n]
return ret[n - 1:] / n
pollutants_A_24hr_avg = moving_mean(pollutants_A, 24)
pollutants_B_8hr_avg = moving_mean(pollutants_B, 8)[-(pollutants_A_24hr_avg.shape[0]):]
現在,我們可以使用 np.concatenate 連接兩個集合,以形成包含所有平均濃度的單個資料集。請注意,我們必須按列連接我們的陣列,因此我們傳遞 axis=1 參數。
pollutants = np.concatenate((pollutants_A_24hr_avg, pollutants_B_8hr_avg), axis=1)
子指標#
每個污染物的子指標都是根據 AQI 和標準斷點範圍之間的線性關係以及上述公式計算得出的
compute_indices 函數首先借助我們上面建立的陣列 AQI 和 breakpoints,取得輸入濃度和污染物的正確 AQI 類別的上限和下限以及斷點濃度。然後,它將這些值輸入到公式中以計算子指標。
def compute_indices(pol, con):
bp = breakpoints[pol]
if pol == 'CO':
inc = 0.1
else:
inc = 1
if bp[0] <= con < bp[1]:
Bl = bp[0]
Bh = bp[1] - inc
Ih = AQI[1] - inc
Il = AQI[0]
elif bp[1] <= con < bp[2]:
Bl = bp[1]
Bh = bp[2] - inc
Ih = AQI[2] - inc
Il = AQI[1]
elif bp[2] <= con < bp[3]:
Bl = bp[2]
Bh = bp[3] - inc
Ih = AQI[3] - inc
Il = AQI[2]
elif bp[3] <= con < bp[4]:
Bl = bp[3]
Bh = bp[4] - inc
Ih = AQI[4] - inc
Il = AQI[3]
elif bp[4] <= con < bp[5]:
Bl = bp[4]
Bh = bp[5] - inc
Ih = AQI[5] - inc
Il = AQI[4]
elif bp[5] <= con:
Bl = bp[5]
Bh = bp[5] + bp[4] - (2 * inc)
Ih = AQI[6]
Il = AQI[5]
else:
print("Concentration out of range!")
return ((Ih - Il) / (Bh - Bl)) * (con - Bl) + Il
我們將使用 np.vectorize 來利用向量化的概念。這僅表示我們不必自己循環遍歷污染物陣列的每個元素。向量化是 NumPy 的主要優勢之一。
vcompute_indices = np.vectorize(compute_indices)
透過為每個污染物呼叫我們的向量化函數 vcompute_indices,我們得到子指標。為了取回具有原始形狀的陣列,我們使用 np.stack。
sub_indices = np.stack((vcompute_indices('PM2.5', pollutants[..., 0]),
vcompute_indices('PM10', pollutants[..., 1]),
vcompute_indices('NO2', pollutants[..., 2]),
vcompute_indices('NH3', pollutants[..., 3]),
vcompute_indices('SO2', pollutants[..., 4]),
vcompute_indices('CO', pollutants[..., 5]),
vcompute_indices('O3', pollutants[..., 6])), axis=1)
空氣品質指標#
使用 np.max,我們找出每個期間的最大子指標,這就是我們的空氣品質指標!
aqi_array = np.max(sub_indices, axis=1)
有了這個,我們就有了 2019 年 6 月 1 日至 2020 年 6 月 30 日每小時的 AQI。請注意,即使我們從 5 月 31 日的資料開始,我們也在移動平均步驟中截斷了該資料。
AQI 的配對學生 t 檢定#
假設檢定是一種描述性統計形式,用於幫助我們根據資料做出決策。從計算出的 AQI 資料中,我們想找出封鎖實施前後的平均 AQI 是否存在統計上的顯著差異。我們將使用左尾配對學生 t 檢定來計算兩個檢定統計量 - t 統計量 和 p 值。然後,我們將把這些與相應的臨界值進行比較以做出決策。

抽樣#
我們現在將原始資料集中的 datetime 列匯入到 datetime64 dtype 陣列中。我們將使用此陣列為 AQI 陣列建立索引並取得資料集的子集。
datetime = np.loadtxt("air-quality-data.csv", dtype='M8[h]', delimiter=",",
skiprows=1, usecols=(0, ))[-(pollutants_A_24hr_avg.shape[0]):]
由於德里自 2020 年 3 月 24 日起開始全面封鎖,因此封鎖後子集的時間段為 2020 年 3 月 24 日至 2020 年 6 月 30 日。封鎖前子集的時間長度與 3 月 24 日之前的時間長度相同。
after_lock = aqi_array[np.where(datetime >= np.datetime64('2020-03-24T00'))]
before_lock = aqi_array[np.where(datetime <= np.datetime64('2020-03-21T00'))][-(after_lock.shape[0]):]
print(after_lock.shape)
print(before_lock.shape)
(2376,)
(2376,)
為了確保我們的樣本大致呈常態分佈,我們取大小為 n = 30 的樣本。before_sample 和 after_sample 是在全面封鎖之前和之後繪製的隨機觀察集。我們使用 random.Generator.choice 來產生樣本。
rng = default_rng()
before_sample = rng.choice(before_lock, size=30, replace=False)
after_sample = rng.choice(after_lock, size=30, replace=False)
定義假設#
讓我們假設封鎖前後的樣本平均值之間沒有顯著差異。這將是虛無假設。備擇假設是平均值之間存在顯著差異,並且 AQI 有所改善。在數學上,
\(H_{0}: \mu_\text{after-before} = 0\)
\(H_{a}: \mu_\text{after-before} < 0\)
計算檢定統計量#
我們將使用 t 統計量來評估我們的假設,甚至從中計算出 p 值。t 統計量的公式為
其中,
\(\mu_\text{after-before}\) = 樣本的平均差異
\(\sigma^{2}\) = 平均差異的變異數
\(n\) = 樣本大小
def t_test(x, y):
diff = y - x
var = np.var(diff, ddof=1)
num = np.mean(diff)
denom = np.sqrt(var / len(x))
return np.divide(num, denom)
t_value = t_test(before_sample, after_sample)
對於 p 值,我們將使用 SciPy 的 stats.distributions.t.cdf() 函數。它採用兩個參數 - t 統計量和自由度 (dof)。dof 的公式為 n - 1。
dof = len(before_sample) - 1
p_value = stats.distributions.t.cdf(t_value, dof)
print("The t value is {} and the p value is {}.".format(t_value, p_value))
The t value is -6.778550885412477 and the p value is 9.648125019613442e-08.
t 和 p 值代表什麼意義?#
我們現在將計算出的檢定統計量與臨界檢定統計量進行比較。臨界 t 值是透過查閱t 分佈表計算得出的。
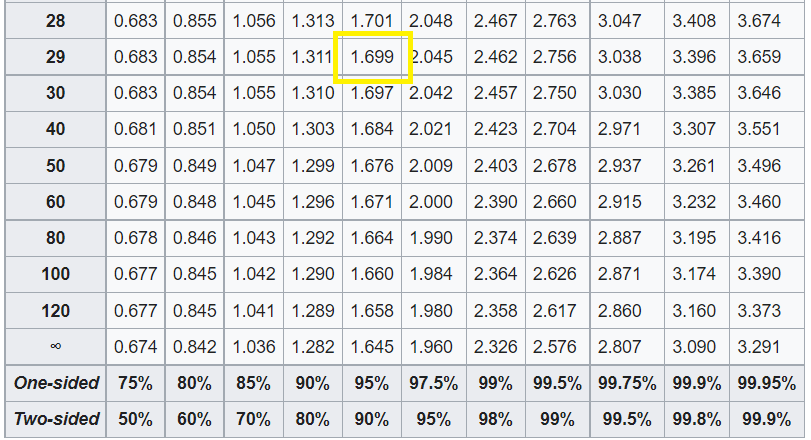
從上表來看,在 95% 的信賴水準下,29 dof 的臨界值為 1.699。由於我們使用的是左尾檢定,因此我們的臨界值為 -1.699。顯然,計算出的 t 值小於臨界值,因此我們可以安全地拒絕虛無假設。
臨界 p 值(以 \(\alpha\) 表示)通常選擇為 0.05,對應於 95% 的信賴水準。如果計算出的 p 值小於 \(\alpha\),則可以安全地拒絕虛無假設。顯然,我們的 p 值遠小於 \(\alpha\),因此我們可以拒絕虛無假設。
請注意,這並不表示我們可以接受備擇假設。它僅告訴我們,沒有足夠的證據來拒絕 \(H_{a}\)。換句話說,我們未能拒絕備擇假設,因此它可能為真。
在實務上…#
對於時間序列資料分析,最好使用 pandas 程式庫。
SciPy stats 模組提供了 stats.ttest_rel 函數,可用於取得
t 統計量和p 值。在現實生活中,資料通常不是常態分佈的。對於此類非常態資料,有一些檢定,例如 Wilcoxon 檢定。