
NEP 47 — 採用陣列 API 標準#
- 作者:
Ralf Gommers <ralf.gommers@gmail.com>
- 作者:
Stephan Hoyer <shoyer@gmail.com>
- 作者:
Aaron Meurer <asmeurer@gmail.com>
- 狀態:
已取代
- 取代者:
- 類型:
標準軌跡
- 建立於:
2021-01-21
- 決議:
注意
此 NEP 已在 NumPy 1.22.0-1.26.x 中以實驗性標籤實作並發布(在匯入時發出警告)。它在 NumPy 2.0.0 之前被移除,NumPy 2.0.0 是 NumPy 在其主要命名空間中獲得陣列 API 標準支援的時間(請參閱 NEP 56 — NumPy 主要命名空間中對陣列 API 標準的支援)。numpy.array_api 的程式碼已移至獨立套件:array-api-strict。如需詳細了解最後一個版本的 numpy.array_api 模組與 numpy 之間的差異,請參閱 1.26.x 文件中的此表格。
摘要#
我們提議採用由 Python 資料 API 標準聯盟 開發的 Python 陣列 API 標準。在 NumPy 中以獨立的新命名空間實作此標準,將允許依賴 NumPy 的程式庫作者以及終端使用者編寫可在 NumPy 和所有其他採用此標準的陣列/張量程式庫之間移植的程式碼。
注意
我們預期此 NEP 將在草案狀態中保留相當長一段時間。鑑於範圍廣泛,我們不預期很快會提議接受它;相反地,我們希望徵求對高階設計和實作的回饋,並了解此 NEP 中需要更好地描述或在實作或陣列 API 標準本身中需要變更的內容。
動機與範疇#
Python 使用者在數值計算、資料科學、機器學習和深度學習的程式庫和框架方面有豐富的選擇。每年都有推動這些領域技術水準的新框架出現。所有這些活動和創造力的意外後果之一是多維陣列(又稱張量)程式庫的分散 - 這是這些領域的基本資料結構。選項包括 NumPy、Tensorflow、PyTorch、Dask、JAX、CuPy、MXNet 等。
這些程式庫的 API 在很大程度上相似,但存在足夠的差異,以至於很難編寫適用於多個(或所有)這些程式庫的程式碼。陣列 API 標準旨在解決此問題,方法是為陣列建構和使用的最常見方式指定 API。擬議的 API 與 NumPy 的 API 非常相似,並且主要在以下情況下偏離:(a)NumPy 做出的設計選擇本質上無法移植到其他實作,以及(b)其他程式庫有目的地持續偏離 NumPy,因為 NumPy 的設計結果證明存在問題或不必要的複雜性。
如需更長篇幅討論陣列 API 標準的目的,我們請您參考 陣列 API 標準的目的與範疇章節,以及宣布聯盟成立的兩篇部落格文章 [1] 和發布標準的第一個草案版本以供社群審閱 [2]。
此 NEP 的範疇包括
採用 2021 年版本的陣列 API 標準
新增獨立的命名空間,暫定名稱為
numpy.array_api新命名空間外部需要/期望的變更,例如
ndarray物件上的新 dunder 方法實作選擇,以及新命名空間中的函數與主要
numpy命名空間中的函數之間的差異符合陣列 API 標準的新陣列物件
維護工作和測試策略
對 NumPy 總暴露 API 介面以及其他未來和正在討論的設計選擇的影響
與現有和擬議的 NumPy 陣列協定 (
__array_ufunc__、__array_function__、__array_module__) 的關係。現有 NumPy 功能所需的改進
此 NEP 的範疇之外是
陣列 API 標準本身的變更。這些變更可能會在此 NEP 的審閱期間出現,但應根據需要向上游推送,並隨後更新此 NEP。
使用方式與影響#
本節將在稍後充實,目前我們請您參考 陣列 API 標準使用案例章節中給出的使用案例
除了這些使用案例之外,新的命名空間還包含許多陣列程式庫廣泛使用和支援的功能。因此,它是一組很好的函數,可以用來教導 NumPy 新手,並推薦作為「最佳實務」。這與 NumPy 的主要命名空間形成對比,NumPy 的主要命名空間包含許多已被取代或我們認為是錯誤的函數和物件 - 但由於向後相容性原因,我們無法移除它們。
下游程式庫使用 numpy.array_api 命名空間的目的是使其能夠使用多種類型的陣列,而無需硬性依賴所有這些陣列程式庫
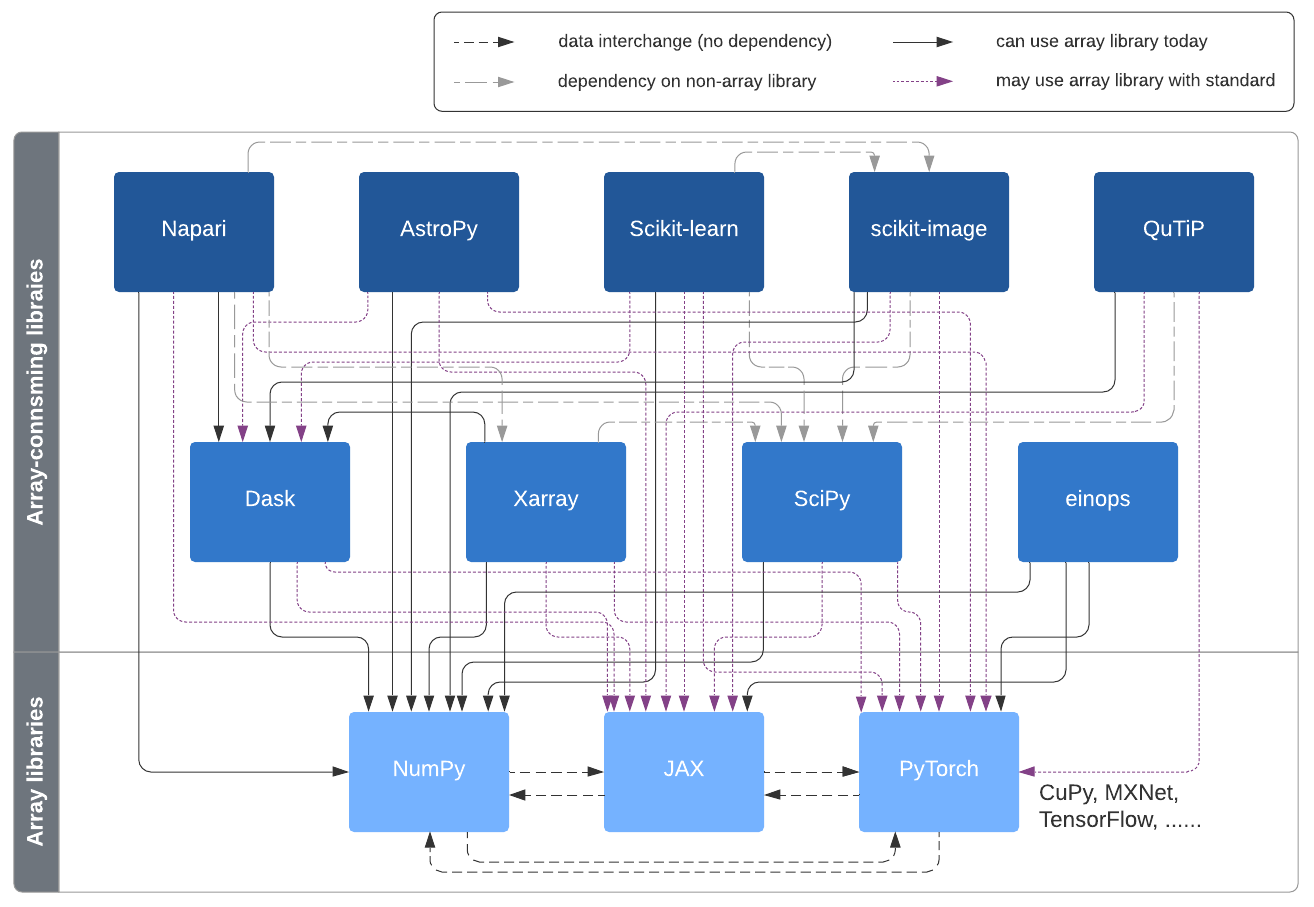
下游程式庫中的採用#
array_api 命名空間的原型實作將與 SciPy、scikit-learn 和其他依賴 NumPy 的感興趣程式庫一起使用,以便獲得更多設計經驗,並找出是否缺少任何重要部分。
支援多個陣列程式庫的模式預期會像這樣
def somefunc(x, y):
# Retrieves standard namespace. Raises if x and y have different
# namespaces. See Appendix for possible get_namespace implementation
xp = get_namespace(x, y)
out = xp.mean(x, axis=0) + 2*xp.std(y, axis=0)
return out
get_namespace 呼叫實際上是程式庫作者選擇加入使用標準 API 命名空間,從而明確支援所有符合規範的陣列程式庫。
asarray / asanyarray 模式#
許多現有的程式庫都使用與 NumPy 本身相同的 asarray(或 asanyarray)模式;接受任何可以強制轉換為 np.ndarray 的物件。我們認為此設計模式有問題 - 請記住 Python 之禪,「顯式優於隱式」,以及該模式在 SciPy 生態系統中對於 ndarray 子類別和過於熱切的物件建立方面歷來存在問題。所有其他陣列/張量程式庫都更嚴格,並且在實務中運作良好。我們建議新程式庫的作者避免使用 asarray 模式。相反地,他們應該只接受 NumPy 陣列,或者如果他們想要支援多種類型的陣列,則檢查傳入的陣列物件是否支援陣列 API 標準,方法是檢查 __array_namespace__,如上面的範例所示。
現有的程式庫也可以執行此類檢查,並且僅在檢查失敗時才呼叫 asarray。這與 NEP 30 — NumPy 陣列的鴨子型別 - 實作 中的 __duckarray__ 概念非常相似。
應用程式程式碼中的採用#
終端使用者可以將新的命名空間視為 NumPy 主要命名空間的清理和精簡版本。鼓勵終端使用者像這樣使用此命名空間
import numpy.array_api as xp
x = xp.linspace(0, 2*xp.pi, num=100)
y = xp.cos(x)
似乎完全合理,並且可能是有益的 - 使用者針對每個目的只獲得一個函數(我們認為的最佳實務),然後他們編寫的程式碼更容易移植到其他程式庫。
向後相容性#
未提議棄用或移除現有的 NumPy API 或其他向後不相容的變更。
高階設計#
陣列 API 標準包含大約 120 個物件,所有這些物件都有直接的 NumPy 等效項。此圖顯示了高階包含的內容
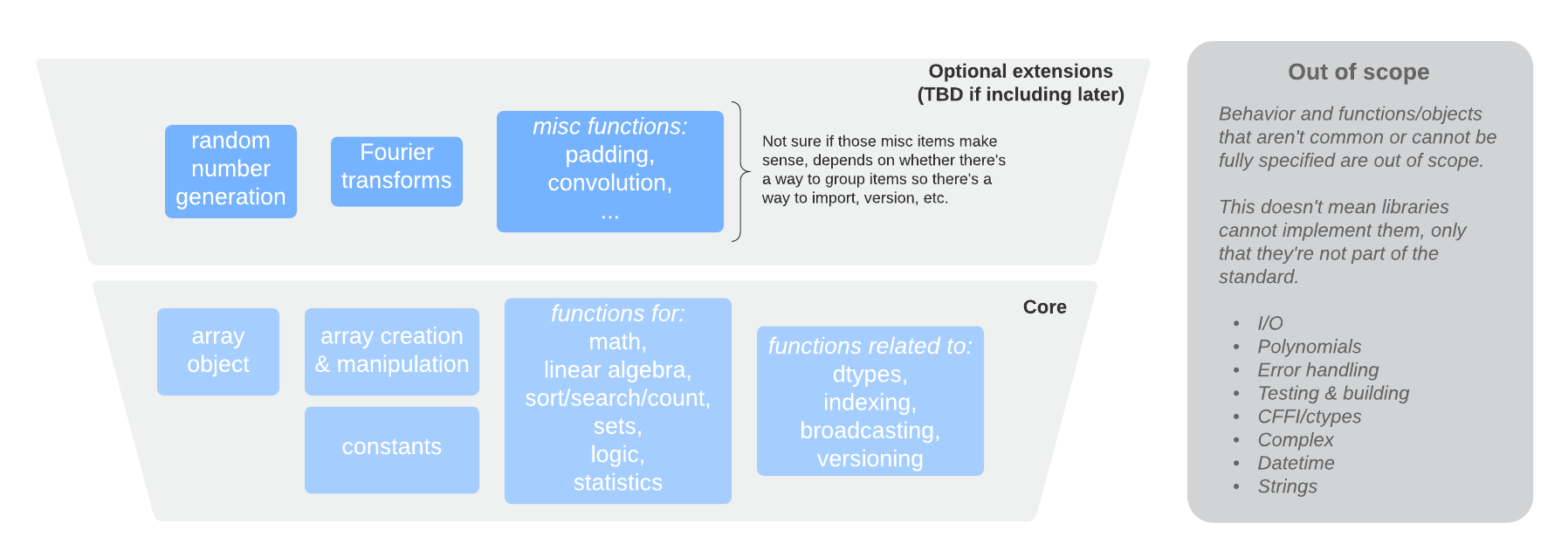
與 NumPy 目前提供的功能相比,最重要的變更是
新的陣列物件,
numpy.array_api.Array,它是
np.ndarray周圍的精簡純 Python(非子類別)包裝器,符合標準指定的轉換規則和索引行為,
除了 dunder 方法外,沒有其他方法,
不支援全方位的 NumPy 索引行為(請參閱下方的 索引),
沒有不同的純量物件,只有 0-D 陣列,
無法直接建構。相反地,應使用陣列建構函數,例如
asarray()。
array_api命名空間中的函數不接受
array_like輸入,僅接受numpy.array_api陣列物件,Python 純量僅在陣列物件上的 dunder 運算子中受支援,不支援
__array_ufunc__和__array_function__,在其簽名中使用僅位置和僅關鍵字參數,
具有內聯類型註解,
與 NumPy 中已存在的等效函數相比,個別函數的簽名和語意可能略有變更,
僅支援 dtype 常值,不支援格式字串或其他指定 dtype 的方式,
一般而言,與 NumPy 對應項相比,可能僅支援受限的 dtype 集合。
DLPack 支援將新增至 NumPy,
將透過新陣列物件上的
.device屬性和array_api命名空間中陣列建立函數中的device=關鍵字新增「裝置支援」的新語法,轉換規則將與 NumPy 目前的規則不同。輸出 dtype 可以從輸入 dtype 衍生而來(即,沒有基於值的轉換),並且 0-D 陣列的處理方式與 >=1-D 陣列相同。不允許跨類型轉換(例如,int 到 float)。
並非 NumPy 擁有的所有 dtype 都是標準的一部分。僅支援布林值、帶符號和不帶符號的整數,以及高達
float64的浮點 dtype。預計在標準的下一個版本中新增複雜 dtype。擴展精度、字串、void、物件和 datetime dtype,以及結構化 dtype,均未包含在內。
現有 NumPy 功能所需的改進包括
將矩陣堆疊支援新增至
numpy.linalg中目前缺少此類支援的某些函數。將
keepdims關鍵字新增至np.argmin和np.argmax。將「永不複製」模式新增至
np.asarray。將 smallest_normal 新增至
np.finfo()。DLPack 支援。
此外,選擇 numpy.array_api 實作作為陣列 API 標準的最小實作。這表示它不僅符合陣列 API 的所有要求,而且明確地不包含標準未明確要求的任何 API 或行為。標準本身不要求實作如此嚴格,但使用 NumPy 陣列 API 實作執行此操作將使其成為陣列 API 標準的標準實作。任何想要使用陣列 API 標準的人都可以使用 NumPy 實作,並確保他們的程式碼沒有使用其他符合規範的實作中可能不存在的行為。
特別是,這表示
numpy.array_api將僅包含標準中列出的那些函數。這也適用於Array物件上的方法,函數將僅接受標準要求的輸入 dtype(例如,
cos等超越函數將不接受整數 dtype,因為標準僅要求它們接受浮點 dtype),類型升級將僅針對標準要求的 dtype 組合發生(請參閱下方的 Dtype 和轉換規則 章節),
索引僅限於可能的索引類型子集(請參閱下方的 索引)。
array_api 命名空間中的函數#
讓我們先從函數實作範例開始,該範例顯示了與主要命名空間中等效函數的最重要差異
def matmul(x1: Array, x2: Array, /) -> Array:
"""
Array API compatible wrapper for :py:func:`np.matmul <numpy.matmul>`.
See its docstring for more information.
"""
if x1.dtype not in _numeric_dtypes or x2.dtype not in _numeric_dtypes:
raise TypeError("Only numeric dtypes are allowed in matmul")
# Call result type here just to raise on disallowed type combinations
_result_type(x1.dtype, x2.dtype)
return Array._new(np.matmul(x1._array, x2._array))
此函數不接受 array_like 輸入,僅接受 numpy.array_api.Array。有多個原因造成這種情況。其他陣列程式庫都以這種方式運作。要求使用者明確地強制轉換 Python 純量、清單、產生器或其他外部物件會產生更簡潔的設計,且意外行為更少。它的效能更高 - 來自 asarray 呼叫的額外負荷更少。靜態類型更容易。子類別將如預期般運作。而且,由於使用者必須在極少數情況下明確強制轉換為 ndarray 而導致的輕微冗長似乎是微不足道的代價。
此函數不支援 __array_ufunc__ 或 __array_function__。這些協定與陣列 API 標準模組本身的目的相似,但透過不同的機制。由於僅接受 Array 實例,因此透過這些協定之一進行調度已不再有用。
此函數在其簽名中使用僅位置參數。這使程式碼更具可移植性 - 例如,編寫 max(a=a, ...) 不再有效,因此如果其他程式庫將第一個參數稱為 input 而不是 a,則沒關係。請注意,NumPy 已經對作為 ufunc 的函數使用僅位置引數。僅關鍵字參數(在上面的範例中未顯示)的理由有兩個:終端使用者程式碼的清晰度,以及更容易在未來擴展簽名,而無需擔心關鍵字的順序。
此函數具有內聯類型註解。內聯註解比單獨的存根檔案更容易維護。而且由於類型很簡單,因此不會像 NumPy 目前擁有的存根檔案那樣,因類型別名或聯合而導致大量混亂。
此函數僅接受數值 dtype(即,不是 bool)。它也不允許輸入 dtype 為不同類型(內部 _result_type() 函數將在跨類型類型組合(如 _result_type(int32, float64))上引發 TypeError)。這允許實作盡可能精簡。防止在 NumPy 中運作但在陣列 API 規格中不需要的組合,讓子模組的使用者知道他們沒有依賴其他程式庫中陣列 API 符合規範的實作中可能不存在的 NumPy 特定行為。
DLPack 支援零複製資料交換#
將一種陣列轉換為另一種陣列的能力很有價值,而且對於下游程式庫想要支援多種類型的陣列而言,實際上是必要的。這需要明確指定的資料交換協定。NumPy 已經支援其中兩個,即緩衝區協定(即 PEP 3118)和 __array_interface__(Python 端)/ __array_struct__(C 端)協定。兩者都以類似的方式運作,讓「生產者」描述資料在記憶體中的佈局方式,以便「消費者」可以使用該資料的視圖建構自己的陣列類型。
DLPack 的運作方式非常相似。優先選擇 DLPack 而不是 NumPy 中已存在的選項的主要原因是
DLPack 是唯一具有裝置支援的協定(例如,使用 CUDA 或 ROCm 驅動程式的 GPU,或 OpenCL 裝置)。NumPy 僅適用於 CPU,但其他陣列程式庫則不然。每個裝置都有一個協定是站不住腳的,因此裝置支援是必須的。
廣泛的支援。DLPack 在所有協定中獲得最廣泛的採用。只有 NumPy 缺少支援,而其他程式庫的經驗是正面的。這與 NumPy 確實支援的協定形成對比,這些協定使用得非常少 - 當其他程式庫想要與 NumPy 互通時,它們通常使用(更受限制且 NumPy 特定的)
__array__協定。
將 DLPack 支援新增至 NumPy 需要
新增
ndarray.__dlpack__()方法,該方法傳回包裝在PyCapsule中的dlpackC 結構。新增
np.from_dlpack(obj)函數,其中obj支援__dlpack__(),並傳回ndarray。
DLPack 目前是一個約 200 LoC 的標頭,旨在直接包含,因此不需要外部依賴項。實作應該很簡單。
裝置支援的語法#
NumPy 本身僅適用於 CPU,因此它顯然不需要裝置支援。但是,其他程式庫(例如 TensorFlow、PyTorch、JAX、MXNet)支援多種類型的裝置:CPU、GPU、TPU 和更奇特的硬體。為了在具有多個裝置的系統上編寫可移植的程式碼,通常需要在與其他陣列相同的裝置上建立新陣列,或檢查兩個陣列是否位於相同的裝置上。因此,需要用於此目的的語法。
陣列物件將具有 .device 屬性,該屬性可讓您比較不同陣列的裝置(僅當兩個陣列都來自相同的程式庫且是相同的硬體裝置時,它們才應該比較相等)。此外,陣列建立函數中需要 device= 關鍵字。例如
def empty(shape: Union[int, Tuple[int, ...]], /, *,
dtype: Optional[dtype] = None,
device: Optional[device] = None) -> Array:
"""
Array API compatible wrapper for :py:func:`np.empty <numpy.empty>`.
"""
if device not in ["cpu", None]:
raise ValueError(f"Unsupported device {device!r}")
return Array._new(np.empty(shape, dtype=dtype))
NumPy 的實作非常簡單,只需將 device 屬性設定為字串 "cpu",如果陣列建立函數遇到任何其他值,則引發例外狀況。
Dtype 和轉換規則#
此命名空間中支援的 dtype 是布林值、8/16/32/64 位元帶符號和不帶符號的整數,以及 32/64 位元浮點 dtype。這些將以預期的名稱(例如,bool、uint16、float64)作為 dtype 常值新增至命名空間。
最明顯的遺漏是複雜 dtype。陣列 API 標準的第一個版本中缺乏複雜支援的原因是,多個程式庫(PyTorch、MXNet)仍在新增對複雜 dtype 的支援。標準的下一個版本預計將包含 complex64 和 complex128(如需更多詳細資訊,請參閱 此問題)。
預期指定函數的 dtype(例如,透過 dtype= 關鍵字)僅使用 dtype 常值。不接受格式字串、Python 內建 dtype 或 dtype 常值的字串表示形式。這將以少量成本提高程式碼的可讀性和可移植性。此外,除了基本相等比較之外,這些 dtype 常值本身不應有任何行為。特別是,由於陣列 API 沒有純量物件,因此不允許使用 float32(0.0) 等語法(可以使用 asarray(0.0, dtype=float32) 建立 0-D 陣列)。
轉換規則僅在相同類型的不同 dtype 之間定義(即,布林值到布林值、整數到整數或浮點到浮點)。這也表示省略了會在 NumPy 中升級為 float64 的整數-uint64 組合。這樣做的理由是,混合類型(例如,整數到浮點)轉換行為在程式庫之間有所不同。
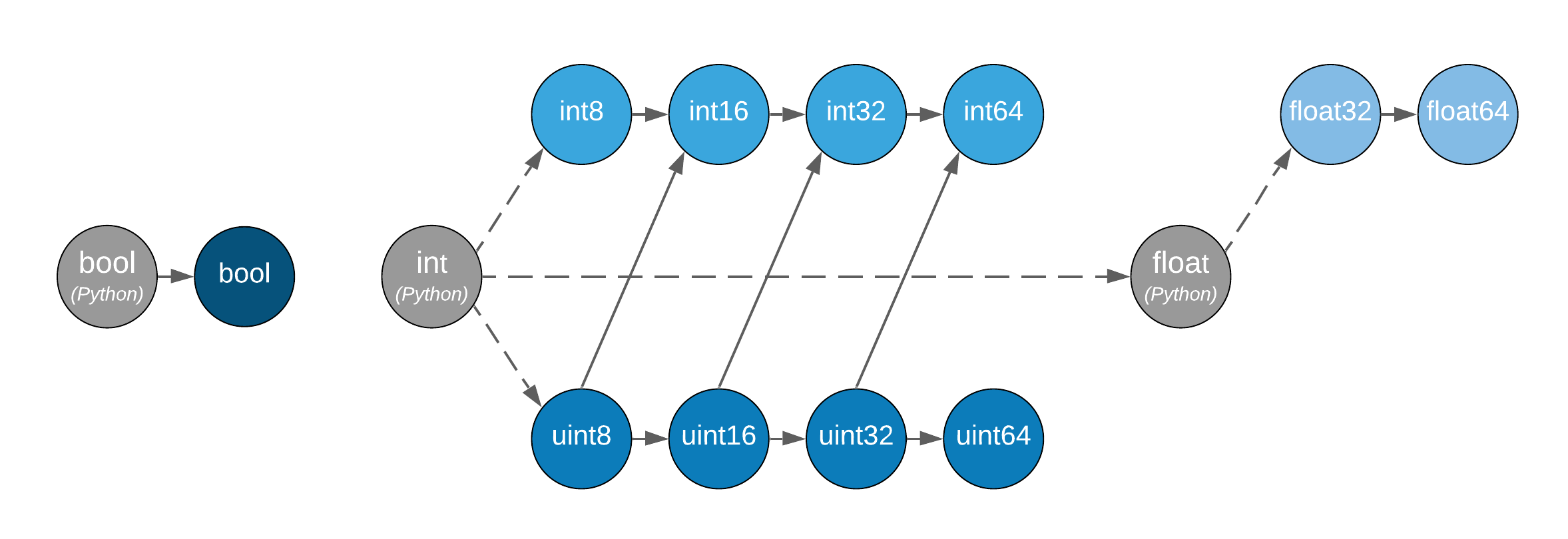
型別提升圖。任何兩種型別之間的提升由它們在此格點上的聯結給出。只有參與陣列的型別重要,而不是它們的值。虛線表示 Python 純量在溢位時的行為未定義。Python 純量本身僅允許在陣列物件上的運算符中使用,而不能在函數內部使用。布林值、整數和浮點 dtype 未連接,表示混合型別提升未定義(對於 NumPy 實作,這些會引發例外)。
NumPy 和陣列 API 標準中鑄造規則最重要的區別在於如何處理純量和 0 維陣列。在標準中,陣列純量不存在,0 維陣列遵循與更高維陣列相同的鑄造規則。此外,標準中沒有基於值的鑄造。運算的結果型別可以完全從其輸入陣列的 dtype 預測,而與它們的形狀或值無關。Python 純量僅允許在雙底線運算(如 __add__)中使用,並且僅當它們與陣列 dtype 的型別相同時才允許。它們始終鑄造到陣列的 dtype,而與值無關。溢位行為未定義。
有關更多詳細資訊,請參閱陣列 API 標準的型別提升規則章節。
在實作中,這表示
確保任何會在 NumPy 中產生純量物件的運算,在
Array建構函式中都轉換為 0-D 陣列,檢查會應用基於值的鑄造的組合,並確保它們提升到正確的型別。這可以透過例如手動廣播 0-D 輸入(防止它們參與基於值的鑄造),或透過顯式將
signature引數傳遞給底層 ufunc 來實現,在雙底線運算符方法中,如果 Python 純量輸入與陣列 dtype 的型別相同,則手動將其轉換為匹配 dtype 的 0-D 陣列,否則引發例外。對於超出給定 dtype 範圍的純量(規格未定義其行為),使用
np.array(scalar, dtype=dtype)的行為(鑄造或引發 OverflowError)。
索引#
會使用 ndarray 傳回純量的索引表達式,例如 arr_2d[0, 0],將傳回具有新 Array 物件的 0-D 陣列。這有幾個原因:陣列純量在很大程度上被認為是設計錯誤,沒有其他陣列庫複製;它更適用於非 CPU 庫(通常陣列可以駐留在裝置上,純量駐留在主機上);而且它只是一個更一致的設計。若要從 0-D 陣列中取得 Python 純量,可以使用該型別的內建函式,例如 float(arr_0d)。
標準中的其他索引模式在很大程度上與它們在 numpy.ndarray 中的行為相同。一個值得注意的區別是,切片索引中的裁剪(例如,a[:n],其中 n 大於第一個軸的大小)是未指定的行為,因為這種檢查在加速器上可能很耗費資源。
標準省略了進階索引(透過整數陣列索引),布林索引僅限於單個 n-D 布林陣列。這是因為這些索引模式不適用於所有型別的陣列或 JIT 編譯。此外,一些進階 NumPy 索引語意,例如在單個索引中混合進階和非進階索引的語意,在 NumPy 中被認為是設計錯誤。缺少這些更進階的索引型別似乎沒有問題;如果使用者或程式庫作者想要使用它們,他們可以透過零複製轉換為 numpy.ndarray 來做到這一點。這將正確地向任何閱讀程式碼的人發出信號,表明它是 NumPy 特有的,而不是可移植到所有符合標準的陣列型別。
作為最小實作,numpy.array_api 將明確禁止具有裁剪邊界的切片、進階索引以及與其他索引混合的布林索引。
陣列物件#
標準中的陣列物件除了雙底線方法外,沒有其他方法。它也不允許直接建構,而是偏好陣列建構方法,例如 asarray。這樣做的理由是並非所有陣列程式庫都在其陣列物件上具有方法(例如,TensorFlow 沒有)。它也僅提供一種執行某項操作的方式,而不是具有有效重複的函數和方法。
混合可能產生視圖的運算(例如,索引、nonzero)與變異(例如,項目或切片賦值)是在標準中明確記錄為不受支援的。這在陣列物件本身中不容易禁止;相反,這將透過文件向使用者提供指導。
標準目前沒有規定陣列物件本身的名稱。我們建議將其命名為 Array。這使用了類別的正確 PEP 8 大寫,並且不與任何現有的 NumPy 類別名稱衝突。[3] 請注意,陣列類別的實際名稱實際上並不那麼重要,因為它本身不包含在頂層命名空間中,並且無法直接建構。
實作#
array_api 命名空間的原型可以在numpy/numpy#18585中找到。其 __init__.py 中的 docstring 對於實作細節有幾個重要的註釋。包裝函式的程式碼也包含 # Note: 註解,標示與 NumPy API 存在差異之處。實作完全使用純 Python,主要由包裝器類別/函數組成,這些類別/函數在應用輸入驗證和任何已變更的行為後,傳遞到對應的 NumPy 函數。尚未實作的一個重要部分是 DLPack 支援,因為其在 np.ndarray 中的實作仍在進行中 (numpy/numpy#19083)。
numpy.array_api 模組被視為實驗性的。這表示匯入它將發出 UserWarning。另一種替代方案是將模組命名為 numpy._array_api,但選擇發出警告而不是重新命名,這樣未來就不必重新命名模組,從而可能破壞使用者程式碼。由於廣泛使用了僅限位置的引數語法,該模組還需要 Python 3.8 或更高版本。
模組的實驗性質也意味著它尚未在 NumPy 文件中的任何地方提及,除了其模組 docstring 和此 NEP 之外。實作的文件本身就是一個具有挑戰性的問題。目前,實作中的每個 docstring 都只是參考它實作的底層 NumPy 函數。然而,這並不理想,因為底層 NumPy 函數的行為可能與陣列 API 中的對應函數不同,例如,陣列 API 中不存在的其他關鍵字引數。有人建議文件可以直接從規格本身提取,但對此的支援需要對規格的編寫方式進行一些技術變更,因此目前的實作尚未嘗試執行此操作。
陣列 API 規格附帶一個正在進行中的官方測試套件,該套件旨在測試任何程式庫是否符合陣列 API 規格。因此,實作中包含的測試將是最小的,因為大部分行為將由此測試套件驗證。array_api 子模組的 NumPy 本身中的測試將僅包括對陣列 API 測試套件未涵蓋的行為進行測試,例如,實作是最小的,並且正確拒絕了不允許的型別組合之類的測試。將在陣列 API 測試套件儲存庫中新增 CI 作業,以定期針對 NumPy 實作進行測試。陣列 API 測試套件旨在供程式庫在需要時進行供應,但此想法被 NumPy 拒絕,因為它所花費的時間相對於現有的 NumPy 測試套件而言非常重要,並且因為測試套件本身仍處於開發階段。
dtype 物件#
我們必須能夠比較 dtype 的相等性,並且必須可以進行以下表達式
np.array_api.some_func(..., dtype=x.dtype)
以上表示最好能有 np.array_api.float32 == np.array_api.ndarray(...).dtype。
使用者不應假設 dtype 具有類別層次結構,但是如果方便的話,我們可以自由地使用類別層次結構來實作它。我們考慮了以下選項來實作 dtype 物件
將 dtype 別名化為主要命名空間中的 dtype,例如,
np.array_api.float32 = np.float32。將 dtype 設為
np.dtype的實例,例如,np.array_api.float32 = np.dtype(np.float32)。建立僅具有所需方法/屬性的新單例類別(目前只有
__eq__)。
從與主要命名空間外部的函數互動的角度來看,(2) 似乎是最容易的,而 (3) 將最符合標準。(2) 不會阻止使用者存取 dtype 物件的 NumPy 特定屬性,而 (3) 會阻止,儘管與 (1) 不同,但它確實禁止建立純量物件,例如 float32(0.0)。(2) 也為每個 dtype 僅保留一個物件—使用 (1),arr.dtype 仍然會是 dtype 實例。實作目前使用 (2)。
待辦事項:標準尚未提供一種很好的方法來檢查 dtype 的屬性,以詢問諸如「這是整數 dtype 嗎?」之類的問題。也許這對使用者來說很容易做到,如下所示
def _get_dtype(dt_or_arr):
return dt_or_arr.dtype if hasattr(dt_or_arr, 'dtype') else dt_or_arr
def is_floating(dtype_or_array):
dtype = _get_dtype(dtype_or_array)
return dtype in (float32, float64)
def is_integer(dtype_or_array):
dtype = _get_dtype(dtype_or_array)
return dtype in (uint8, uint16, uint32, uint64, int8, int16, int32, int64)
但是,將其新增到標準中可能是有意義的。請注意,NumPy 本身目前沒有很好的方法來詢問此類問題,請參閱 gh-17325。
替代方案#
有人提議將 NumPy 陣列 API 實作作為與 NumPy 分離的程式庫。此提議被拒絕,因為將其分離會降低人們審查它的可能性,並且將其作為實驗性子模組包含在 NumPy 本身中,將使已經依賴 NumPy 的終端使用者和程式庫作者更容易存取實作。
附錄 - 可能的 get_namespace 實作#
在應用程式程式碼中的採用章節中提到的 get_namespace 函數可以像這樣實作
def get_namespace(*xs):
# `xs` contains one or more arrays, or possibly Python scalars (accepting
# those is a matter of taste, but doesn't seem unreasonable).
namespaces = {
x.__array_namespace__() if hasattr(x, '__array_namespace__') else None for x in xs if not isinstance(x, (bool, int, float, complex))
}
if not namespaces:
# one could special-case np.ndarray above or use np.asarray here if
# older numpy versions need to be supported.
raise ValueError("Unrecognized array input")
if len(namespaces) != 1:
raise ValueError(f"Multiple namespaces for array inputs: {namespaces}")
xp, = namespaces
if xp is None:
raise ValueError("The input is not a supported array type")
return xp
討論#
參考文獻和腳註#
版權#
本文檔已置於公共領域。[1]