
NEP 13 — 覆寫 UFunc 機制#
- 作者:
Blake Griffith
- 聯絡方式:
- 日期:
2013-07-10
- 作者:
Pauli Virtanen
- 作者:
Nathaniel Smith
- 作者:
Marten van Kerkwijk
- 作者:
Stephan Hoyer
- 日期:
2017-03-31
- 狀態:
最終
- 更新日期:
2023-02-19
- 作者:
Roy Smart
摘要#
NumPy 的通用函數 (ufunc) 目前對於使用 __array_prepare__ 和 __array_wrap__ 操作 ndarray 的使用者定義子類別有一些有限的功能 [1],並且幾乎或完全不支援任意物件。例如,SciPy 的稀疏矩陣 [2] [3]。
在此,我們提議加入一種機制來覆寫 ufunc,該機制基於 ufunc 檢查其每個參數是否具有 __array_ufunc__ 方法。在發現 __array_ufunc__ 時,ufunc 將把操作交給該方法。
這涵蓋了與 Travis Oliphant 關於使用多重方法改造 NumPy 的提案部分相同的內容 [4],這將解決相同的問題。此處的機制更密切地遵循 Python 使類別能夠覆寫 __mul__ 和其他二元運算的方式。它也特別說明了二元運算子和 ufunc 應如何互動。(請注意,在較早的版本中,覆寫稱為 __numpy_ufunc__。已經進行了實作,但行為不太正確,因此更改了名稱。)
如下所述的 __array_ufunc__ 要求任何對應的 Python 二元運算(__mul__ 等)都應以特定方式實作,並且與 NumPy 的 ndarray 語意相容。不滿足此條件的物件無法覆寫任何 NumPy ufunc。我們沒有指定未來相容的路徑來放寬此要求 — 此處的任何變更都需要第三方程式碼的相應變更。
動機#
目前用於調度 Ufunc 的機制普遍認為是不夠的。已經有長時間的討論和其他提出的解決方案 [5], [6]。
將 ufunc 與 ndarray 的子類別一起使用僅限於 __array_prepare__ 和 __array_wrap__ 來準備輸出參數,但這些不允許您例如變更參數的形狀或資料。嘗試對不屬於 ndarray 子類別的事物使用 ufunc 甚至更加困難,因為輸入參數傾向於轉換為物件陣列,最終會產生令人驚訝的結果。
以稀疏矩陣的 ufunc 互操作性為例。
In [1]: import numpy as np
import scipy.sparse as sp
a = np.random.randint(5, size=(3,3))
b = np.random.randint(5, size=(3,3))
asp = sp.csr_matrix(a)
bsp = sp.csr_matrix(b)
In [2]: a, b
Out[2]:(array([[0, 4, 4],
[1, 3, 2],
[1, 3, 1]]),
array([[0, 1, 0],
[0, 0, 1],
[4, 0, 1]]))
In [3]: np.multiply(a, b) # The right answer
Out[3]: array([[0, 4, 0],
[0, 0, 2],
[4, 0, 1]])
In [4]: np.multiply(asp, bsp).todense() # calls __mul__ which does matrix multi
Out[4]: matrix([[16, 0, 8],
[ 8, 1, 5],
[ 4, 1, 4]], dtype=int64)
In [5]: np.multiply(a, bsp) # Returns NotImplemented to user, bad!
Out[5]: NotImplemented
不應將 NotImplemented 返回給使用者。此外
In [6]: np.multiply(asp, b)
Out[6]: array([[ <3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>],
[ <3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>],
[ <3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>]], dtype=object)
在此,稀疏矩陣似乎已轉換為物件陣列純量值,然後與 b 陣列的所有元素相乘。但是,此行為比有用的行為更令人困惑,並且最好產生 TypeError。
此提案不會解決 scipy.sparse 矩陣的問題,其乘法語意與 NumPy 陣列不相容。但是,目標是啟用撰寫其他具有嚴格 ndarray 相容語意的自訂陣列類型。
提議的介面#
標準陣列類別 ndarray 獲得了 __array_ufunc__ 方法,物件可以透過覆寫此方法(如果它們是 ndarray 子類別)或定義自己的方法來覆寫 Ufunc。方法簽名為
def __array_ufunc__(self, ufunc, method, *inputs, **kwargs)
在此
ufunc 是被呼叫的 ufunc 物件。
method 是一個字串,指示 Ufunc 的呼叫方式,可以是
"__call__"以指示它是直接呼叫,或是其方法之一:"reduce"、"accumulate"、"reduceat"、"outer"或"at"。inputs 是 ufunc 的輸入參數的元組
kwargs 包含傳遞給函數的任何選用或關鍵字參數。這包括任何
out參數,這些參數始終包含在元組中。
因此,參數已正規化:只有必要的輸入參數 (inputs) 作為位置參數傳遞,所有其他參數都作為關鍵字參數的字典 (kwargs) 傳遞。特別是,如果有輸出參數(無論位置或其他方式),且不是 None,則它們會作為元組在 out 關鍵字參數中傳遞(即使對於 reduce、accumulate 和 reduceat 方法,在所有目前情況下,只有單一輸出才有意義)。
函數調度按以下方式進行
如果輸入、輸出或
where參數之一實作了__array_ufunc__,則會執行它而不是 ufunc。如果多個參數實作了
__array_ufunc__,則會依以下順序嘗試它們:子類別優先於超類別,輸入優先於輸出,輸出優先於where,否則從左到右。第一個傳回非
NotImplemented的__array_ufunc__方法決定 Ufunc 的傳回值。如果輸入參數的所有
__array_ufunc__方法都傳回NotImplemented,則會引發TypeError。如果
__array_ufunc__方法引發錯誤,則會立即傳播該錯誤。如果沒有任何輸入參數具有
__array_ufunc__方法,則執行會退回預設的 ufunc 行為。
在上述情況中,有一個但書:如果一個類別具有 __array_ufunc__ 屬性,但它與 ndarray.__array_ufunc__ 相同,則該屬性將被忽略。ndarray 的實例和未覆寫其繼承的 __array_ufunc__ 實作的 ndarray 子類別會發生這種情況。
類型轉換層級#
Python 運算子覆寫機制在如何撰寫覆寫方法方面提供了很大的自由度,並且需要一定的紀律才能獲得可預測的結果。在此,我們討論一種理解某些含義的方法,這可以為設計提供輸入。
保持清楚了解哪些類型可以「向上轉換」為其他類型,可能是間接地(例如,實作了間接 A->B->C,但未實作直接 A->C)。如果 __array_ufunc__ 的實作遵循一致的類型轉換層級,則可以用於理解運算的結果。
類型轉換可以表示為如下定義的 圖形
對於每個
__array_ufunc__方法,從每個可能的輸入類型繪製到每個可能的輸出類型的有向邊。也就是說,在
y = x.__array_ufunc__(a, b, c, ...)執行了除傳回NotImplemented或引發錯誤以外的操作的每種情況下,繪製邊type(a)->type(y)、type(b)->type(y)、…
如果產生的圖形是非循環的,則它定義了一致的類型轉換層級(類型之間明確的部分排序)。在這種情況下,涉及多種類型的運算通常可預測地產生「最高」類型的結果,或引發 TypeError。請參閱本節末尾的範例。
如果圖形有循環,則 __array_ufunc__ 類型轉換未明確定義,並且諸如 type(multiply(a, b)) != type(multiply(b, a)) 或 type(add(a, add(b, c))) != type(add(add(a, b), c)) 之類的事情並非不可能(然後可能總是可能的)。
如果類型轉換層級明確定義,則對於每個類別 A,所有其他定義 __array_ufunc__ 的類別都恰好屬於以下三個群組之一
高於 A:A 可以在 ufunc 中(間接)向上轉換的類型。
低於 A:可以在 ufunc 中(間接)向上轉換為 A 的類型。
不相容:既不高於也不低於 A;無法進行(間接)向上轉換的類型。
請注意,NumPy ufunc 的傳統行為是嘗試透過 np.asarray() 將未知物件轉換為 ndarray。這相當於將 ndarray 放置在圖形中這些物件的上方。由於我們在上面定義 ndarray 對於具有自訂 __array_ufunc__ 的類別傳回 NotImplemented,因此這會將 ndarray 放置在類型層級中此類別的下方,從而允許覆寫運算。
鑑於以上所述,描述可傳遞運算的二元 ufunc 應旨在定義明確定義的轉換層級。這也可能是所有 ufunc 的明智方法 — 對此的例外情況應仔細考慮是否會產生任何令人驚訝的行為結果。
範例
類型轉換層級。
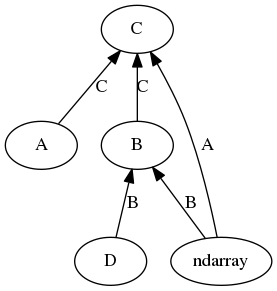
類型 A 的 __array_ufunc__ 可以處理傳回 C 的 ndarray,B 可以處理傳回 B 的 ndarray 和 D,而 C 可以處理傳回 C 的 A 和 B,但不能處理 ndarray 或 D。結果是一個有向非循環圖,並定義了類型轉換層級,關係為 C > A、C > ndarray、C > B > ndarray、C > B > D。類型 A 與 B、D、ndarray 不相容,而 D 與 A 和 ndarray 不相容。涉及這些類別的 Ufunc 運算式應產生涉及的最高類型的結果或引發 TypeError。
範例
__array_ufunc__ 圖形中的單一循環。

在這種情況下,__array_ufunc__ 關係具有長度為 1 的循環,並且類型轉換層級不存在。二元運算不可交換:type(a + b) 為 A,但 type(b + a) 為 B。
範例
__array_ufunc__ 圖形中的較長循環。
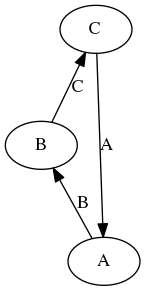
在這種情況下,__array_ufunc__ 關係具有較長的循環,並且類型轉換層級不存在。二元運算仍然可交換,但類型傳遞性遺失:type(a + (b + c)) 為 A,但 type((a + b) + c) 為 C。
子類別層級#
一般而言,最好在 ufunc 類型轉換層級中鏡射類別層級。建議類別的 __array_ufunc__ 實作通常應傳回 NotImplemented,除非輸入是相同類別或超類別的實例。這保證在類型轉換層級中,超類別在下方,子類別在上方,而其他類別不相容。對此的例外情況需要檢查它們是否尊重隱含的類型轉換層級。
注意
請注意,此處定義的類型轉換層級和類別層級朝「相反」方向發展。原則上,讓 __array_ufunc__ 也處理子類別的實例也是一致的。在這種情況下,「子類別優先」調度規則將確保相對相似的結果。但是,行為的指定就不那麼明確了。
如果方法一致地使用 super() 傳遞類別層級,則可以輕鬆建構子類別。為了支援這一點,ndarray 具有自己的 __array_ufunc__ 方法,相當於
def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
# Cannot handle items that have __array_ufunc__ (other than our own).
outputs = kwargs.get('out', ())
objs = inputs + outputs
if "where" in kwargs:
objs = objs + (kwargs["where"], )
for item in objs:
if (hasattr(item, '__array_ufunc__') and
type(item).__array_ufunc__ is not ndarray.__array_ufunc__):
return NotImplemented
# If we didn't have to support legacy behaviour (__array_prepare__,
# __array_wrap__, etc.), we might here convert python floats,
# lists, etc, to arrays with
# items = [np.asarray(item) for item in inputs]
# and then start the right iterator for the given method.
# However, we do have to support legacy, so call back into the ufunc.
# Its arguments are now guaranteed not to have __array_ufunc__
# overrides, and it will do the coercion to array for us.
return getattr(ufunc, method)(*items, **kwargs)
請注意,作為一種特殊情況,ufunc 調度機制不會呼叫此 ndarray.__array_ufunc__ 方法,即使對於尚未覆寫預設 ndarray 實作的 ndarray 子類別也是如此。因此,呼叫 ndarray.__array_ufunc__ 不會導致巢狀 ufunc 調度循環。
對於僅新增諸如單位之類的屬性的 ndarray 子類別,super() 的使用應特別有用。在其 __array_ufunc__ 實作中,此類別可以對與其自身類別相關的參數進行可能的調整,並使用 super() 傳遞給超類別實作,直到 ufunc 實際完成,然後對輸出進行可能的調整。
一般而言,__array_ufunc__ 的自訂實作應避免巢狀調度循環,其中不僅透過 getattr(ufunc, method)(*items, **kwargs) 呼叫 ufunc,而且還捕獲可能的例外情況等。與往常一樣,可能會有例外情況。例如,對於像 MaskedArray 這樣的類別,它只關心它包含的任何內容是否是 ndarray 子類別,透過 __array_ufunc__ 重新實作可能更容易透過直接將 ufunc 應用於其資料,然後調整遮罩來完成。實際上,可以將此視為類別確定它是否可以處理另一個參數的一部分(即,它在類型層級中的位置)。在這種情況下,如果試驗失敗,則應傳回 NotImplemented。因此,實作會像這樣
def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
# for simplicity, outputs are ignored here.
unmasked_items = tuple((item.data if isinstance(item, MaskedArray)
else item) for item in inputs)
try:
unmasked_result = getattr(ufunc, method)(*unmasked_items, **kwargs)
except TypeError:
return NotImplemented
# for simplicity, ignore that unmasked_result could be a tuple
# or a scalar.
if not isinstance(unmasked_result, np.ndarray):
return NotImplemented
# now combine masks and view as MaskedArray instance
...
作為一個具體範例,考慮一個 quantity 和一個 masked array 類別,它們都覆寫了 __array_ufunc__,其中包含特定實例 q 和 ma,後者包含一個常規陣列。執行 np.multiply(q, ma) 時,ufunc 將首先調度到 q.__array_ufunc__,後者傳回 NotImplemented(因為 quantity 類別將自身轉換為陣列並呼叫 super(),後者傳遞給 ndarray.__array_ufunc__,後者看到 ma 上的覆寫)。接下來,ma.__array_ufunc__ 獲得機會。它不知道 quantity,如果它也只傳回 NotImplemented,則會產生 TypeError。但在我們的範例實作中,它使用 getattr(ufunc, method) 來有效地評估 np.multiply(q, ma.data)。這將再次傳遞給 q.__array_ufunc__,但這次,由於 ma.data 是一個常規陣列,它將傳回也是一個 quantity 的結果。由於這是 ndarray 的子類別,因此 ma.__array_ufunc__ 可以將其轉換為遮罩陣列,從而傳回結果(顯然,如果它不是陣列子類別,它仍然可以傳回 NotImplemented)。
請注意,在上面討論的類型層級的上下文中,這是一個有點棘手的範例,因為 MaskedArray 具有奇怪的位置:它高於 ndarray 的所有子類別,因為它可以將它們轉換為自己的類型,但它本身不知道如何在 ufunc 中與它們互動。
關閉 Ufunc#
對於某些類別,Ufunc 沒有意義,並且與某些其他特殊方法(例如 __hash__ 和 __iter__ [8])一樣,可以透過將 __array_ufunc__ 設定為 None 來指示 Ufunc 不可用。如果對任何將 __array_ufunc__ = None 的運算元呼叫 Ufunc,它將無條件引發 TypeError。
在類型轉換層級中,這明確表示類型相對於 ndarray 不相容。
與 Python 二元運算結合的行為#
NumPy ndarray 中的 Python 運算子覆寫機制與 __array_ufunc__ 機制相關聯。對於特殊方法呼叫,例如 Python 為實作二元運算(如 * 和 +)而呼叫的 ndarray.__mul__(self, other),NumPy 的 ndarray 實作了以下行為:
如果
other.__array_ufunc__ is None,ndarray會回傳NotImplemented。控制權會回到 Python,Python 接著會嘗試呼叫other上對應的反身方法(例如,other.__rmul__),如果有的話。如果
other上沒有__array_ufunc__屬性,且other.__array_priority__ > self.__array_priority__,ndarray也會回傳NotImplemented(且邏輯流程與前一種情況相同)。這確保了與舊版 NumPy 的回溯相容性。否則,
ndarray會單方面呼叫對應的 Ufunc。Ufunc 永遠不會回傳NotImplemented,因此,**如果__array_ufunc__設定為None以外的任何值,則無法使用反身方法(例如other.__rmul__)來覆寫 NumPy 陣列的算術運算**。相反地,它們的行為需要透過實作與對應 Ufunc(例如,np.multiply)一致的__array_ufunc__來變更。請參閱 運算子與 NumPy Ufunc 的清單,以取得受影響的運算子及其對應 ufunc 的清單。
因此,希望修改二元運算中與 ndarray 互動的類別有兩種選擇:
實作二元運算的建議#
對於大多數數值類別而言,覆寫二元運算最簡單的方式是定義 __array_ufunc__ 並覆寫對應的 Ufunc。然後,該類別可以像 ndarray 本身一樣,根據 Ufunc 定義二元運算子。在此,必須謹慎確保允許其他類別表明它們不相容,也就是說,實作應該類似於:
def _disables_array_ufunc(obj):
try:
return obj.__array_ufunc__ is None
except AttributeError:
return False
class ArrayLike:
...
def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
...
return result
# Option 1: call ufunc directly
def __mul__(self, other):
if _disables_array_ufunc(other):
return NotImplemented
return np.multiply(self, other)
def __rmul__(self, other):
if _disables_array_ufunc(other):
return NotImplemented
return np.multiply(other, self)
def __imul__(self, other):
return np.multiply(self, other, out=(self,))
# Option 2: call into one's own __array_ufunc__
def __mul__(self, other):
return self.__array_ufunc__(np.multiply, '__call__', self, other)
def __rmul__(self, other):
return self.__array_ufunc__(np.multiply, '__call__', other, self)
def __imul__(self, other):
result = self.__array_ufunc__(np.multiply, '__call__', self, other,
out=(self,))
if result is NotImplemented:
raise TypeError(...)
為了理解為什麼需要謹慎,請考慮另一個類別 other,它不知道如何處理陣列和 ufunc,因此將 __array_ufunc__ 設定為 None,但知道如何進行乘法運算:
class MyObject:
__array_ufunc__ = None
def __init__(self, value):
self.value = value
def __repr__(self):
return "MyObject({!r})".format(self.value)
def __mul__(self, other):
return MyObject(1234)
def __rmul__(self, other):
return MyObject(4321)
對於上述任一選項,我們都會得到預期的結果:
mine = MyObject(0)
arr = ArrayLike([0])
mine * arr # -> MyObject(1234)
mine *= arr # -> MyObject(1234)
arr * mine # -> MyObject(4321)
arr *= mine # -> TypeError
在此,在第一個和第二個範例中,會呼叫 mine.__mul__(arr),並立即得到結果。在第三個範例中,首先呼叫 arr.__mul__(mine)。在選項 (1) 中,對 mine.__array_ufunc__ is None 的檢查將會成功,因此會回傳 NotImplemented,這會導致執行 mine.__rmul__(arg)。在選項 (2) 中,很可能在 arr.__array_ufunc__ 內部,會清楚知道無法處理另一個引數,並再次回傳 NotImplemented,導致控制權傳遞給 mine.__rmul__。
對於第四個範例,使用就地運算子,我們在此遵循 ndarray,並確保我們永遠不會回傳 NotImplemented,而是引發 TypeError。在選項 (1) 中,這會間接發生:我們傳遞給 np.multiply,而 np.multiply 又會立即引發 TypeError,因為它的其中一個運算元 (out[0]) 停用了 Ufunc。在選項 (2) 中,我們直接傳遞給 arr.__array_ufunc__,它會回傳 NotImplemented,而我們會捕捉到它。
注意
不允許就地運算回傳 NotImplemented 的原因是,這些運算無法通用地由簡單的反向運算取代:大多數陣列運算假設執行個體的內容會就地變更,而不期望新的執行個體。此外,ndarr[:] *= mine 會暗示什麼?假設它的意思是 ndarr[:] = ndarr[:] * mine,如同 python 在 ndarr.__imul__ 要回傳 NotImplemented 時的預設行為,這很可能是錯誤的。
現在考慮如果我們沒有新增檢查會發生什麼事。對於選項 (1),相關的情況是如果我們沒有檢查 __array_func__ 是否設定為 None。在第三個範例中,呼叫了 arr.__mul__(mine),如果沒有檢查,這會轉到 np.multiply(arr, mine)。這會嘗試 arr.__array_ufunc__,它會回傳 NotImplemented,並看到 mine.__array_ufunc__ is None,因此會引發 TypeError。
對於選項 (2),相關的範例是第四個,使用 arr *= mine:如果我們讓 NotImplemented 通過,python 會將其替換為 arr = mine.__rmul__(arr),這不是我們想要的。
由於 Ufunc 覆寫和 Python 二元運算的語意幾乎相同,因此在大多數情況下,選項 (1) 和 (2) 會產生相同的結果,並使用相同的 __array_ufunc__ 實作。一個例外是當第二個引數是第一個引數的子類別時,實作的嘗試順序,這是由於 Python 錯誤 [9],預計在 Python 3.7 中修復。
一般而言,我們建議採用選項 (1),這是與 ndarray 本身使用的選項最相似的選項。請注意,選項 (1) 具有傳染性,因為任何其他希望支援與您的類別進行二元運算的類別,現在也必須遵循這些規則,以支援與 ndarray 進行二元算術運算(也就是說,它們必須實作 __array_ufunc__ 或將其設定為 None)。我們認為這是一件好事,因為它可以確保 ufunc 和支援它們的所有物件上的算術運算的一致性。
為了簡化實作此類陣列類別,mixin 類別 NDArrayOperatorsMixin 為所有具有對應 Ufunc 的二元運算子提供了選項 (1) 樣式的覆寫。希望為相容版本的 NumPy 實作 __array_ufunc__,但也需要在舊版本上支援與 NumPy 陣列進行二元算術運算的類別,應確保 __array_ufunc__ 也可用於實作它們支援的所有二元運算。
最後,我們注意到我們曾廣泛討論過,要求像 MyObject 這樣的類別實作完整的 __array_ufunc__ 是否更有意義 [6]。最終,允許類別選擇退出是更受歡迎的,而上述推理使我們同意為 ndarray 本身採用類似的實作。選擇退出機制需要停用 Ufunc,因此類別無法定義 Ufunc 來回傳與對應二元運算不同的結果(也就是說,如果定義了 np.add(x, y),它應該與 x + y 相符)。我們的目標是盡可能簡化與 NumPy 陣列進行二元運算的派送邏輯,使其可以同時使用 Python 的派送規則或 NumPy 的派送規則,而不是兩者的混合。
運算子與 NumPy Ufunc 的清單#
以下是 Python 二元運算子和 ndarray 和 NDArrayOperatorsMixin 使用的對應 NumPy Ufunc 的完整清單:
符號 |
運算子 |
NumPy Ufunc(s) |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NA |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
尚未作為 ufunc 實作 [11] |
以下是單元運算子的清單:
符號 |
運算子 |
NumPy Ufunc(s) |
|---|---|---|
|
|
|
|
|
|
NA |
|
|
|
|
|
未來擴展到其他函式#
某些 NumPy 函式可以實作為(廣義)Ufunc,在這種情況下,它們可以被 __array_ufunc__ 方法覆寫。主要的候選者是 matmul(),它目前不是 Ufunc,但可以相對容易地重寫為(一組)廣義 Ufunc。諸如 median()、min() 和 argsort() 等函式也可能發生同樣的情況。