

NumPy:初學者絕對基礎指南#
歡迎來到 NumPy 初學者絕對基礎指南!
NumPy (Numerical Python) 是一個開源的 Python 函式庫,廣泛應用於科學與工程領域。NumPy 函式庫包含多維陣列資料結構,例如同質的 N 維 ndarray,以及大量有效率地操作這些資料結構的函式庫。在什麼是 NumPy了解更多關於 NumPy 的資訊,如果您有任何意見或建議,請聯繫我們!
如何匯入 NumPy#
在安裝 NumPy之後,可以像這樣將其匯入 Python 程式碼中
import numpy as np
這種廣泛使用的慣例允許使用簡短且可識別的前綴 (np.) 存取 NumPy 功能,同時將 NumPy 功能與其他同名功能區分開來。
閱讀範例程式碼#
在整個 NumPy 文件中,您會找到如下所示的程式碼區塊
>>> a = np.array([[1, 2, 3],
... [4, 5, 6]])
>>> a.shape
(2, 3)
以 >>> 或 ... 開頭的文字是輸入,即您在腳本或 Python 提示字元中輸入的程式碼。其他所有內容都是輸出,即執行程式碼的結果。請注意,>>> 和 ... 不是程式碼的一部分,如果在 Python 提示字元中輸入,可能會導致錯誤。
為什麼要使用 NumPy?#
Python 列表是非常棒的通用容器。它們可以是「異質的」,意味著它們可以包含各種型別的元素,而且當用於對少量元素執行個別操作時,它們速度相當快。
根據資料的特性和需要執行的操作型別,其他容器可能更適合;透過利用這些特性,我們可以提高速度、減少記憶體消耗,並提供高階語法來執行各種常見的處理任務。當有大量「同質」(相同型別)資料需要在 CPU 上處理時,NumPy 就會發光發熱。
什麼是「陣列」?#
在電腦程式設計中,陣列是一種用於儲存和檢索資料的結構。我們經常談論陣列,彷彿它是一個空間中的網格,每個單元格儲存一個資料元素。例如,如果資料的每個元素都是一個數字,我們可能會將「一維」陣列視覺化為列表
二維陣列就像一個表格
三維陣列就像一組表格,可能像印在不同頁面上那樣堆疊起來。在 NumPy 中,這個概念被推廣到任意數量的維度,因此基本的陣列類別稱為 ndarray:它代表「N 維陣列」。
大多數 NumPy 陣列都有一些限制。例如
陣列的所有元素都必須是相同的資料型別。
一旦建立,陣列的總大小就不能改變。
形狀必須是「矩形的」,而不是「鋸齒狀的」;例如,二維陣列的每一列都必須具有相同的欄數。
當滿足這些條件時,NumPy 會利用這些特性使陣列比限制較少的資料結構更快、更節省記憶體且更方便使用。
在本文件的其餘部分,我們將使用「陣列」一詞來指稱 ndarray 的實例。
陣列基礎#
初始化陣列的一種方法是使用 Python 序列,例如列表。例如
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a
array([1, 2, 3, 4, 5, 6])
陣列的元素可以透過各種方式存取。例如,我們可以像存取原始列表中的元素一樣存取此陣列的個別元素:使用方括號中元素的整數索引。
>>> a[0]
1
注意
與內建的 Python 序列一樣,NumPy 陣列是「從 0 開始索引」的:陣列的第一個元素是使用索引 0 存取的,而不是 1。
與原始列表一樣,陣列是可變的。
>>> a[0] = 10
>>> a
array([10, 2, 3, 4, 5, 6])
也與原始列表一樣,Python 切片表示法可以用於索引。
>>> a[:3]
array([10, 2, 3])
一個主要的區別是,列表的切片索引會將元素複製到新列表中,但陣列的切片會返回一個視圖:一個指向原始陣列中資料的物件。可以使用視圖來修改原始陣列。
>>> b = a[3:]
>>> b
array([4, 5, 6])
>>> b[0] = 40
>>> a
array([ 10, 2, 3, 40, 5, 6])
有關陣列運算何時返回視圖而不是副本的更全面說明,請參閱副本與視圖。
二維和更高維度的陣列可以從巢狀 Python 序列初始化
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
>>> a
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
在 NumPy 中,陣列的維度有時稱為「軸」。此術語可能有用於消除陣列的維度與陣列表示的資料的維度之間的歧義。例如,陣列 a 可以表示三個點,每個點都位於四維空間內,但 a 只有兩個「軸」。
陣列和列表的列表之間的另一個區別是,可以透過在單個方括號集中指定沿每個軸的索引(以逗號分隔)來存取陣列的元素。例如,元素 8 位於第 1 行和第 3 列
>>> a[1, 3]
8
注意
在數學中,通常的做法是先用列索引,後用欄索引來指稱矩陣的元素。這對於二維陣列來說正好是正確的,但更好的心智模型是將欄索引視為最後,而將列索引視為倒數第二。這可以推廣到具有任意維度數量的陣列。
注意
您可能會聽到 0 維(零維)陣列稱為「純量」,1 維(一維)陣列稱為「向量」,2 維(二維)陣列稱為「矩陣」,或 N 維(N 維,其中「N」通常是數字大於 2 的整數)陣列稱為「張量」。為了清楚起見,在指稱陣列時最好避免使用數學術語,因為具有這些名稱的數學物件的行為與陣列不同(例如,「矩陣」乘法與「陣列」乘法從根本上不同),並且科學 Python 生態系統中還有其他具有這些名稱的物件(例如,PyTorch 的基本資料結構是「張量」)。
陣列屬性#
本節涵蓋陣列的 ndim、shape、size 和 dtype 屬性。
陣列的維度數包含在 ndim 屬性中。
>>> a.ndim
2
陣列的形狀是一個非負整數的元組,用於指定沿每個維度的元素數量。
>>> a.shape
(3, 4)
>>> len(a.shape) == a.ndim
True
陣列中固定的元素總數包含在 size 屬性中。
>>> a.size
12
>>> import math
>>> a.size == math.prod(a.shape)
True
陣列通常是「同質的」,意味著它們僅包含一種「資料型別」的元素。資料型別記錄在 dtype 屬性中。
>>> a.dtype
dtype('int64') # "int" for integer, "64" for 64-bit
如何建立基本陣列#
本節涵蓋 np.zeros()、np.ones()、np.empty()、np.arange()、np.linspace()
除了從元素序列建立陣列之外,您還可以輕鬆建立一個填充 0 的陣列
>>> np.zeros(2)
array([0., 0.])
或一個填充 1 的陣列
>>> np.ones(2)
array([1., 1.])
甚至是空陣列!函式 empty 建立一個陣列,其初始內容是隨機的,並且取決於記憶體的狀態。使用 empty 而不是 zeros(或類似的東西)的原因是速度 - 只要確保之後填充每個元素即可!
>>> # Create an empty array with 2 elements
>>> np.empty(2)
array([3.14, 42. ]) # may vary
您可以建立一個具有一定範圍元素的陣列
>>> np.arange(4)
array([0, 1, 2, 3])
甚至是一個包含一定範圍均勻間隔的陣列。為此,您需要指定第一個數字、最後一個數字和步長。
>>> np.arange(2, 9, 2)
array([2, 4, 6, 8])
您也可以使用 np.linspace() 來建立一個陣列,其值在指定的間隔內線性間隔
>>> np.linspace(0, 10, num=5)
array([ 0. , 2.5, 5. , 7.5, 10. ])
指定您的資料型別
雖然預設資料型別是浮點數 (np.float64),但您可以使用 dtype 關鍵字明確指定您想要的資料型別。
>>> x = np.ones(2, dtype=np.int64)
>>> x
array([1, 1])
新增、移除和排序元素#
本節涵蓋 np.sort()、np.concatenate()
使用 np.sort() 排序陣列非常簡單。您可以在呼叫函式時指定軸、種類和順序。
如果您從這個陣列開始
>>> arr = np.array([2, 1, 5, 3, 7, 4, 6, 8])
您可以透過以下方式快速將數字按升序排序
>>> np.sort(arr)
array([1, 2, 3, 4, 5, 6, 7, 8])
除了 sort(返回陣列的排序副本)之外,您還可以使用的函式包括
argsort,它是沿指定軸的間接排序,lexsort,它是多個鍵的間接穩定排序,searchsorted,它將在已排序的陣列中查找元素,以及partition,它是部分排序。
若要閱讀更多關於排序陣列的資訊,請參閱:sort。
如果您從這些陣列開始
>>> a = np.array([1, 2, 3, 4])
>>> b = np.array([5, 6, 7, 8])
您可以使用 np.concatenate() 將它們串連起來。
>>> np.concatenate((a, b))
array([1, 2, 3, 4, 5, 6, 7, 8])
或者,如果您從這些陣列開始
>>> x = np.array([[1, 2], [3, 4]])
>>> y = np.array([[5, 6]])
您可以使用以下方式將它們串連起來
>>> np.concatenate((x, y), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
為了從陣列中移除元素,使用索引來選擇您想要保留的元素非常簡單。
若要閱讀更多關於串連的資訊,請參閱:concatenate。
您如何知道陣列的形狀和大小?#
本節涵蓋 ndarray.ndim、ndarray.size、ndarray.shape
ndarray.ndim 將告訴您陣列的軸數或維度。
ndarray.size 將告訴您陣列的元素總數。這是陣列形狀元素的乘積。
ndarray.shape 將顯示一個整數元組,指示沿陣列每個維度儲存的元素數量。例如,如果您有一個具有 2 列和 3 欄的二維陣列,則陣列的形狀為 (2, 3)。
例如,如果您建立此陣列
>>> array_example = np.array([[[0, 1, 2, 3],
... [4, 5, 6, 7]],
...
... [[0, 1, 2, 3],
... [4, 5, 6, 7]],
...
... [[0 ,1 ,2, 3],
... [4, 5, 6, 7]]])
若要查找陣列的維度數,請執行
>>> array_example.ndim
3
若要查找陣列中的元素總數,請執行
>>> array_example.size
24
若要查找陣列的形狀,請執行
>>> array_example.shape
(3, 2, 4)
您可以重塑陣列嗎?#
本節涵蓋 arr.reshape()
是的!
使用 arr.reshape() 將為陣列提供新形狀,而不會更改資料。請記住,當您使用 reshape 方法時,您想要產生的陣列需要與原始陣列具有相同數量的元素。如果您從一個具有 12 個元素的陣列開始,則需要確保您的新陣列也總共有 12 個元素。
如果您從這個陣列開始
>>> a = np.arange(6)
>>> print(a)
[0 1 2 3 4 5]
您可以使用 reshape() 來重塑陣列。例如,您可以將此陣列重塑為具有三列和兩欄的陣列
>>> b = a.reshape(3, 2)
>>> print(b)
[[0 1]
[2 3]
[4 5]]
使用 np.reshape,您可以指定一些可選參數
>>> np.reshape(a, shape=(1, 6), order='C')
array([[0, 1, 2, 3, 4, 5]])
a 是要重塑的陣列。
shape 是您想要的新形狀。您可以指定整數或整數元組。如果您指定整數,則結果將是該長度的陣列。形狀應與原始形狀相容。
order: C 表示使用 C 樣式索引順序讀取/寫入元素,F 表示使用 Fortran 樣式索引順序讀取/寫入元素,A 表示如果 a 在記憶體中是 Fortran 連續的,則使用 Fortran 樣式索引順序讀取/寫入元素,否則使用 C 樣式順序。(這是一個可選參數,不需要指定。)
如果您想了解更多關於 C 和 Fortran 順序的資訊,您可以在此處閱讀更多關於 NumPy 陣列內部組織的資訊。基本上,C 和 Fortran 順序與索引如何對應於陣列在記憶體中儲存的順序有關。在 Fortran 中,當在記憶體中儲存的二維陣列的元素之間移動時,第一個索引是變化最快的索引。由於第一個索引在更改時移動到下一列,因此矩陣一次儲存一欄。這就是為什麼 Fortran 被認為是以欄為主語言。另一方面,在 C 中,最後一個索引變化最快。矩陣按列儲存,使其成為以列為主語言。您對 C 或 Fortran 執行的操作取決於保留索引慣例或不重新排序資料是否更重要。
如何將一維陣列轉換為二維陣列(如何向陣列新增新軸)#
本節涵蓋 np.newaxis、np.expand_dims
您可以使用 np.newaxis 和 np.expand_dims 來增加現有陣列的維度。
使用 np.newaxis 將在使用一次時將陣列的維度增加一個維度。這表示 1D 陣列將變成 2D 陣列,2D 陣列將變成 3D 陣列,依此類推。
例如,如果您從這個陣列開始
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a.shape
(6,)
您可以使用 np.newaxis 新增新軸
>>> a2 = a[np.newaxis, :]
>>> a2.shape
(1, 6)
您可以使用 np.newaxis 將一維陣列明確轉換為列向量或行向量。例如,您可以透過沿第一個維度插入軸將一維陣列轉換為列向量
>>> row_vector = a[np.newaxis, :]
>>> row_vector.shape
(1, 6)
或者,對於行向量,您可以沿第二個維度插入軸
>>> col_vector = a[:, np.newaxis]
>>> col_vector.shape
(6, 1)
您也可以使用 np.expand_dims 在指定位置插入新軸來擴展陣列。
例如,如果您從這個陣列開始
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a.shape
(6,)
您可以使用 np.expand_dims 在索引位置 1 新增軸,如下所示
>>> b = np.expand_dims(a, axis=1)
>>> b.shape
(6, 1)
您可以使用以下方式在索引位置 0 新增軸
>>> c = np.expand_dims(a, axis=0)
>>> c.shape
(1, 6)
在此處找到更多關於 newaxis 的資訊,並在expand_dims 找到 expand_dims 的資訊。
索引和切片#
您可以像對 Python 列表進行切片一樣,對 NumPy 陣列進行索引和切片。
>>> data = np.array([1, 2, 3])
>>> data[1]
2
>>> data[0:2]
array([1, 2])
>>> data[1:]
array([2, 3])
>>> data[-2:]
array([2, 3])
您可以這樣視覺化它

您可能想要取得陣列的某個部分或特定陣列元素,以用於進一步分析或其他操作。為此,您需要對陣列進行子集化、切片和/或索引。
如果您想要從陣列中選擇滿足特定條件的值,使用 NumPy 非常簡單。
例如,如果您從這個陣列開始
>>> a = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
您可以輕鬆印出陣列中小於 5 的所有值。
>>> print(a[a < 5])
[1 2 3 4]
您也可以選擇例如大於或等於 5 的數字,並使用該條件來索引陣列。
>>> five_up = (a >= 5)
>>> print(a[five_up])
[ 5 6 7 8 9 10 11 12]
您可以選擇可被 2 整除的元素
>>> divisible_by_2 = a[a%2==0]
>>> print(divisible_by_2)
[ 2 4 6 8 10 12]
或者,您可以使用 & 和 | 運算子選擇滿足兩個條件的元素
>>> c = a[(a > 2) & (a < 11)]
>>> print(c)
[ 3 4 5 6 7 8 9 10]
您也可以使用邏輯運算子 & 和 | 來返回布林值,這些布林值指定陣列中的值是否滿足特定條件。這對於包含名稱或其他類別值的陣列很有用。
>>> five_up = (a > 5) | (a == 5)
>>> print(five_up)
[[False False False False]
[ True True True True]
[ True True True True]]
您也可以使用 np.nonzero() 從陣列中選擇元素或索引。
從這個陣列開始
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
您可以使用 np.nonzero() 印出例如小於 5 的元素的索引
>>> b = np.nonzero(a < 5)
>>> print(b)
(array([0, 0, 0, 0]), array([0, 1, 2, 3]))
在此範例中,返回了一個陣列元組:每個維度一個。第一個陣列表示找到這些值的列索引,第二個陣列表示找到這些值的欄索引。
如果您想要產生元素存在的座標列表,您可以壓縮陣列,迭代座標列表,然後印出它們。例如
>>> list_of_coordinates= list(zip(b[0], b[1]))
>>> for coord in list_of_coordinates:
... print(coord)
(np.int64(0), np.int64(0))
(np.int64(0), np.int64(1))
(np.int64(0), np.int64(2))
(np.int64(0), np.int64(3))
您也可以使用 np.nonzero() 印出陣列中小於 5 的元素,如下所示
>>> print(a[b])
[1 2 3 4]
如果您要查找的元素在陣列中不存在,則返回的索引陣列將為空。例如
>>> not_there = np.nonzero(a == 42)
>>> print(not_there)
(array([], dtype=int64), array([], dtype=int64))
閱讀更多關於使用 nonzero 函式的資訊,請參閱:nonzero。
如何從現有資料建立陣列#
本節涵蓋 切片 和 索引、np.vstack()、np.hstack()、np.hsplit()、.view()、copy()
您可以輕鬆地從現有陣列的一部分建立新陣列。
假設您有這個陣列
>>> a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
您可以隨時透過指定要對陣列進行切片的位置,從陣列的一部分建立新陣列。
>>> arr1 = a[3:8]
>>> arr1
array([4, 5, 6, 7, 8])
在這裡,您從索引位置 3 到索引位置 8(但不包括位置 8 本身)抓取了陣列的一部分。
提醒:陣列索引從 0 開始。這表示陣列的第一個元素位於索引 0,第二個元素位於索引 1,依此類推。
您也可以垂直和水平堆疊兩個現有陣列。假設您有兩個陣列,a1 和 a2
>>> a1 = np.array([[1, 1],
... [2, 2]])
>>> a2 = np.array([[3, 3],
... [4, 4]])
您可以使用 vstack 垂直堆疊它們
>>> np.vstack((a1, a2))
array([[1, 1],
[2, 2],
[3, 3],
[4, 4]])
或使用 hstack 水平堆疊它們
>>> np.hstack((a1, a2))
array([[1, 1, 3, 3],
[2, 2, 4, 4]])
您可以使用 hsplit 將陣列分割成多個較小的陣列。您可以指定要返回的形狀相等的陣列數量,也可以指定應該在之後進行分割的欄。
假設您有這個陣列
>>> x = np.arange(1, 25).reshape(2, 12)
>>> x
array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]])
如果您想要將此陣列分割成三個形狀相等的陣列,您將執行
>>> np.hsplit(x, 3)
[array([[ 1, 2, 3, 4],
[13, 14, 15, 16]]), array([[ 5, 6, 7, 8],
[17, 18, 19, 20]]), array([[ 9, 10, 11, 12],
[21, 22, 23, 24]])]
如果您想要在第三欄和第四欄之後分割陣列,您將執行
>>> np.hsplit(x, (3, 4))
[array([[ 1, 2, 3],
[13, 14, 15]]), array([[ 4],
[16]]), array([[ 5, 6, 7, 8, 9, 10, 11, 12],
[17, 18, 19, 20, 21, 22, 23, 24]])]
您可以使用 view 方法建立一個新的陣列物件,該物件查看與原始陣列相同的資料(淺拷貝)。
視圖是 NumPy 的重要概念!NumPy 函式以及索引和切片等運算將在可能的情況下返回視圖。這可以節省記憶體並更快(無需製作資料副本)。但是,務必注意這一點 - 修改視圖中的資料也會修改原始陣列!
假設您建立此陣列
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
現在我們透過對 a 進行切片來建立陣列 b1,並修改 b1 的第一個元素。這也將修改 a 中的對應元素!
>>> b1 = a[0, :]
>>> b1
array([1, 2, 3, 4])
>>> b1[0] = 99
>>> b1
array([99, 2, 3, 4])
>>> a
array([[99, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
使用 copy 方法將製作陣列及其資料的完整副本(深拷貝)。若要在您的陣列上使用此方法,您可以執行
>>> b2 = a.copy()
基本陣列運算#
本節涵蓋加法、減法、乘法、除法等等
一旦您建立了陣列,就可以開始使用它們。例如,假設您建立了兩個陣列,一個稱為「data」,另一個稱為「ones」

您可以使用加號將陣列加在一起。
>>> data = np.array([1, 2])
>>> ones = np.ones(2, dtype=int)
>>> data + ones
array([2, 3])
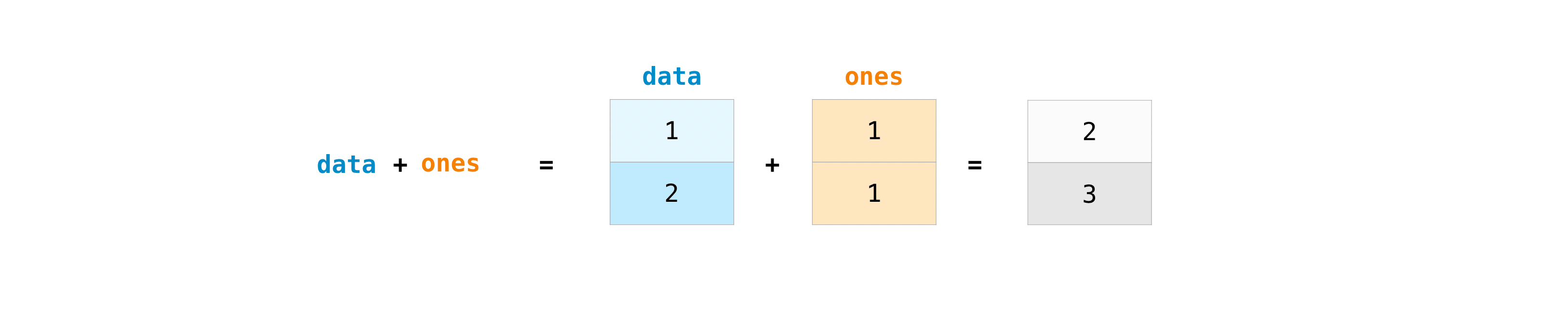
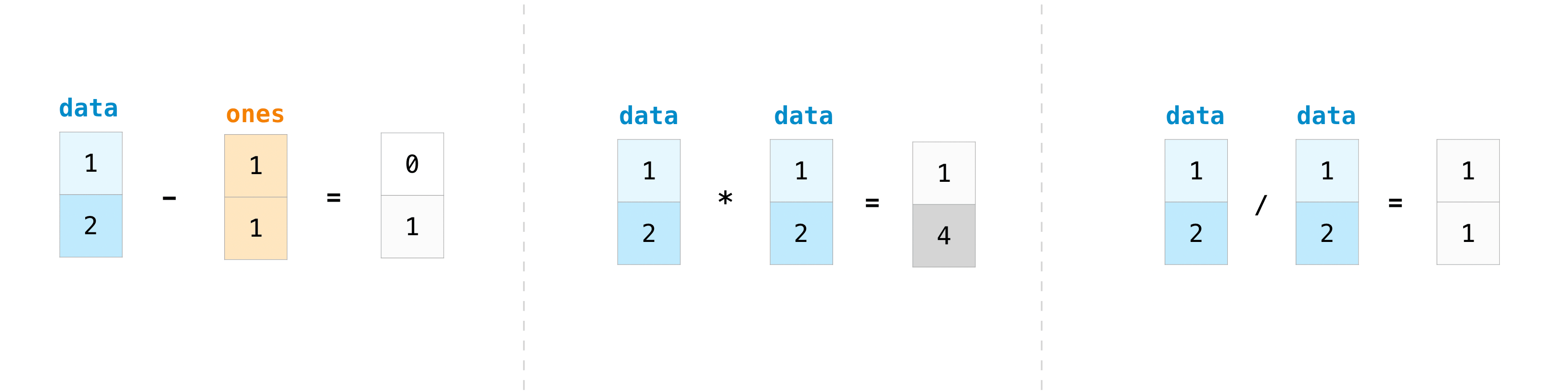
當然,您可以做的不僅僅是加法!
>>> data - ones
array([0, 1])
>>> data * data
array([1, 4])
>>> data / data
array([1., 1.])
基本運算對於 NumPy 來說很簡單。如果您想要查找陣列中元素的總和,您可以使用 sum()。這適用於一維陣列、二維陣列和更高維度的陣列。
>>> a = np.array([1, 2, 3, 4])
>>> a.sum()
10
若要新增二維陣列中的列或欄,您需要指定軸。
如果您從這個陣列開始
>>> b = np.array([[1, 1], [2, 2]])
您可以使用以下方式對列軸求和
>>> b.sum(axis=0)
array([3, 3])
您可以使用以下方式對欄軸求和
>>> b.sum(axis=1)
array([2, 4])
廣播#
有時您可能想要在陣列和單個數字之間(也稱為向量和純量之間的運算)或在兩個不同大小的陣列之間執行運算。例如,您的陣列(我們稱之為「data」)可能包含關於英里距離的資訊,但您想要將資訊轉換為公里。您可以使用以下方式執行此運算
>>> data = np.array([1.0, 2.0])
>>> data * 1.6
array([1.6, 3.2])
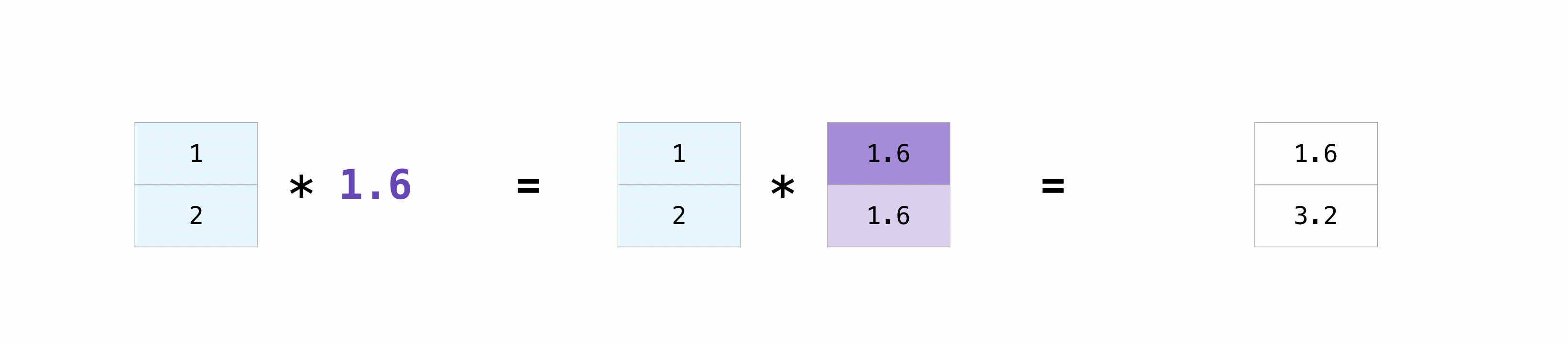
NumPy 了解乘法應該與每個單元格一起發生。這個概念稱為廣播。廣播是一種機制,允許 NumPy 對不同形狀的陣列執行運算。陣列的維度必須相容,例如,當兩個陣列的維度相等時,或當其中一個陣列的維度為 1 時。如果維度不相容,您將收到 ValueError。
更多有用的陣列運算#
本節涵蓋最大值、最小值、總和、平均值、乘積、標準差等等
NumPy 也執行聚合函式。除了 min、max 和 sum 之外,您可以輕鬆執行 mean 來取得平均值,prod 來取得元素相乘的結果,std 來取得標準差等等。
>>> data.max()
2.0
>>> data.min()
1.0
>>> data.sum()
3.0
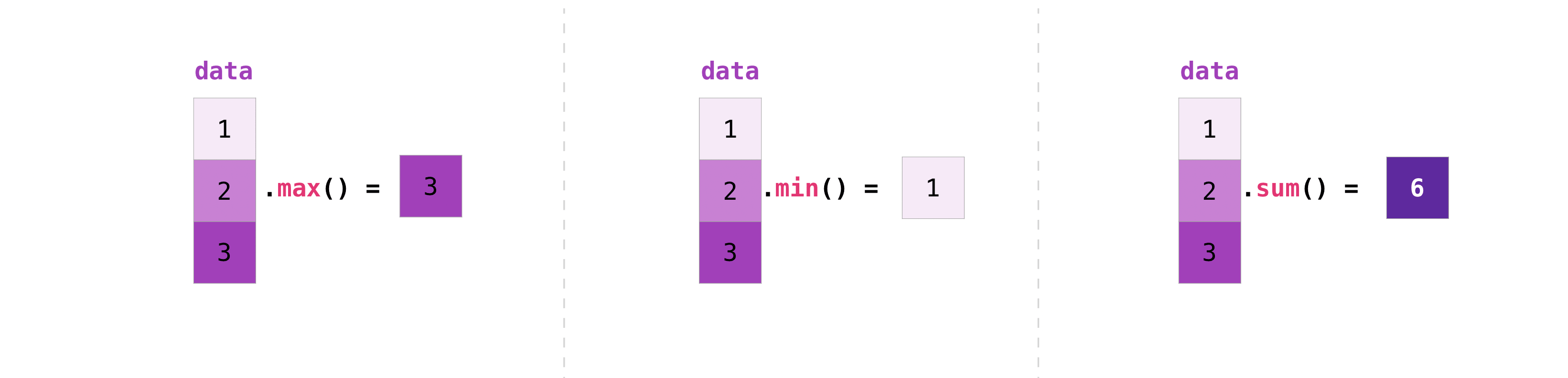
讓我們從這個稱為「a」的陣列開始
>>> a = np.array([[0.45053314, 0.17296777, 0.34376245, 0.5510652],
... [0.54627315, 0.05093587, 0.40067661, 0.55645993],
... [0.12697628, 0.82485143, 0.26590556, 0.56917101]])
通常需要沿列或欄聚合。預設情況下,每個 NumPy 聚合函式都將返回整個陣列的聚合。若要查找陣列中元素的總和或最小值,請執行
>>> a.sum()
4.8595784
或
>>> a.min()
0.05093587
您可以指定要計算聚合函式的軸。例如,您可以透過指定 axis=0 來查找每欄中的最小值。
>>> a.min(axis=0)
array([0.12697628, 0.05093587, 0.26590556, 0.5510652 ])
上面列出的四個值對應於陣列中的欄數。對於四欄陣列,您將獲得四個值作為結果。
在此處閱讀更多關於陣列方法的資訊。
建立矩陣#
您可以傳遞 Python 列表的列表來建立二維陣列(或「矩陣」),以在 NumPy 中表示它們。
>>> data = np.array([[1, 2], [3, 4], [5, 6]])
>>> data
array([[1, 2],
[3, 4],
[5, 6]])

當您操作矩陣時,索引和切片運算很有用
>>> data[0, 1]
2
>>> data[1:3]
array([[3, 4],
[5, 6]])
>>> data[0:2, 0]
array([1, 3])

您可以像聚合向量一樣聚合矩陣
>>> data.max()
6
>>> data.min()
1
>>> data.sum()
21
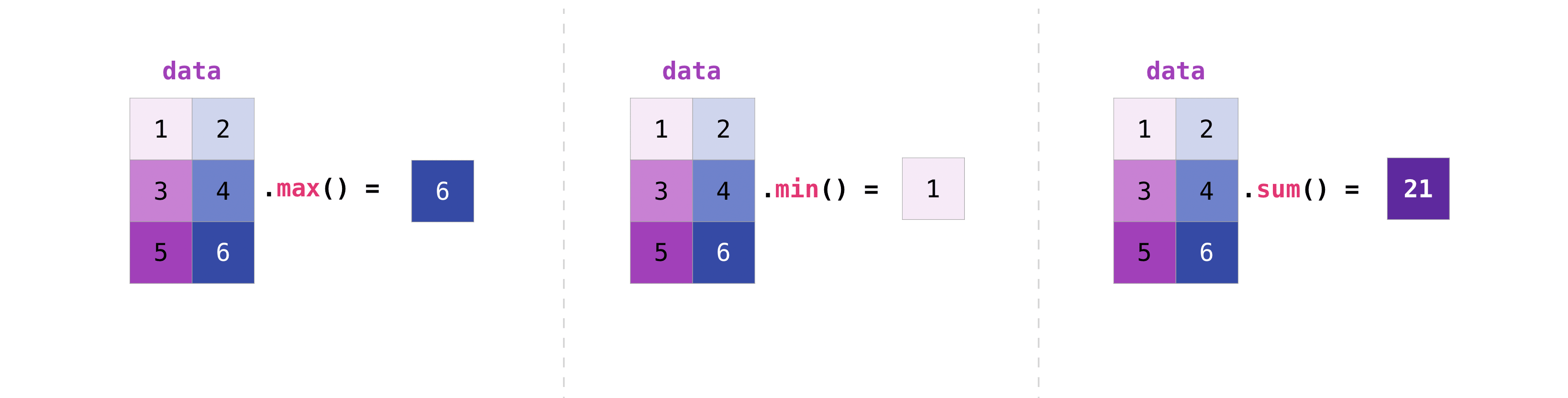
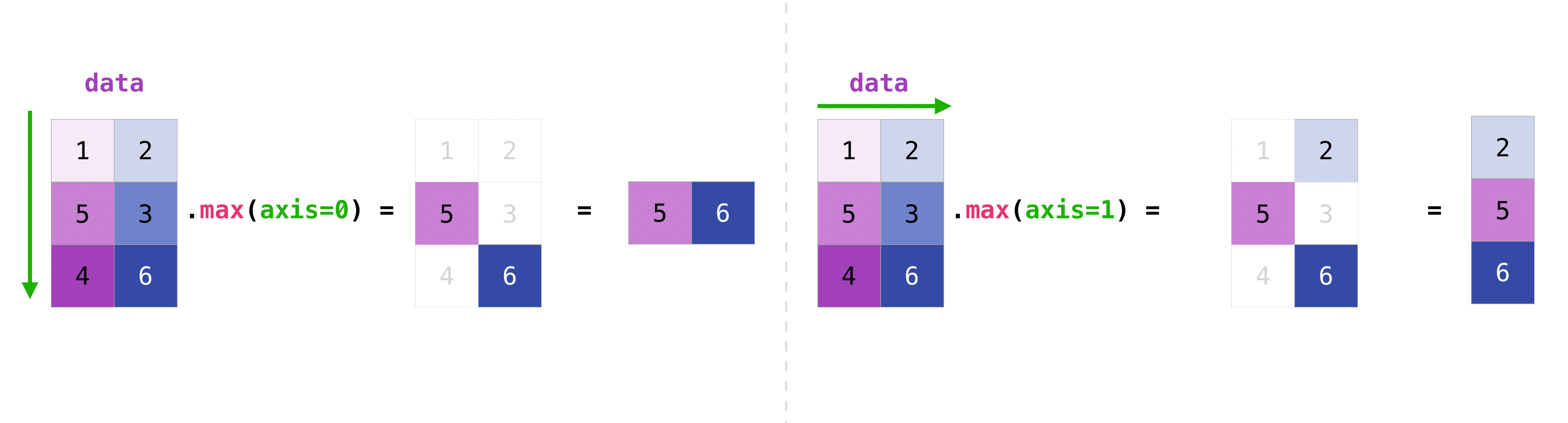
您可以聚合矩陣中的所有值,也可以使用 axis 參數跨欄或列聚合它們。為了說明這一點,讓我們看一下稍微修改過的資料集
>>> data = np.array([[1, 2], [5, 3], [4, 6]])
>>> data
array([[1, 2],
[5, 3],
[4, 6]])
>>> data.max(axis=0)
array([5, 6])
>>> data.max(axis=1)
array([2, 5, 6])
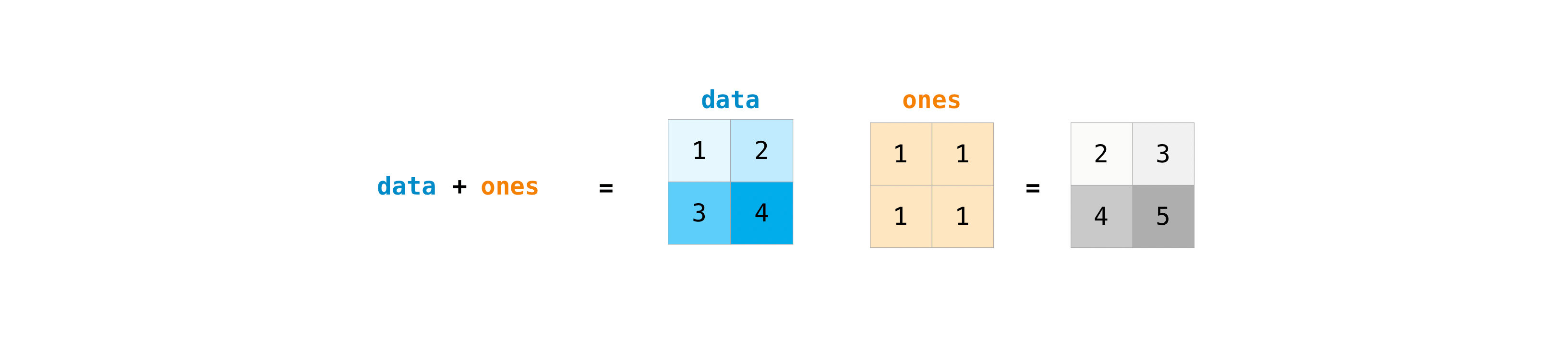
一旦您建立了矩陣,如果兩個矩陣的大小相同,則可以使用算術運算子來加法和乘法它們。
>>> data = np.array([[1, 2], [3, 4]])
>>> ones = np.array([[1, 1], [1, 1]])
>>> data + ones
array([[2, 3],
[4, 5]])
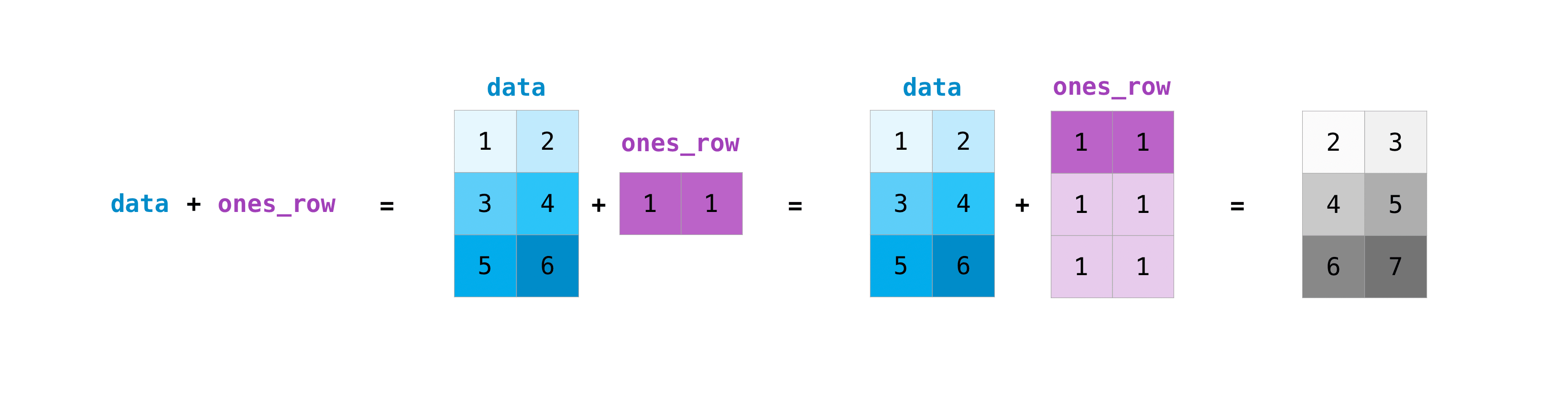
您可以在大小不同的矩陣上執行這些算術運算,但前提是其中一個矩陣只有一欄或一列。在這種情況下,NumPy 將對運算使用其廣播規則。
>>> data = np.array([[1, 2], [3, 4], [5, 6]])
>>> ones_row = np.array([[1, 1]])
>>> data + ones_row
array([[2, 3],
[4, 5],
[6, 7]])
請注意,當 NumPy 印出 N 維陣列時,最後一個軸的迴圈速度最快,而第一個軸的速度最慢。例如
>>> np.ones((4, 3, 2))
array([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
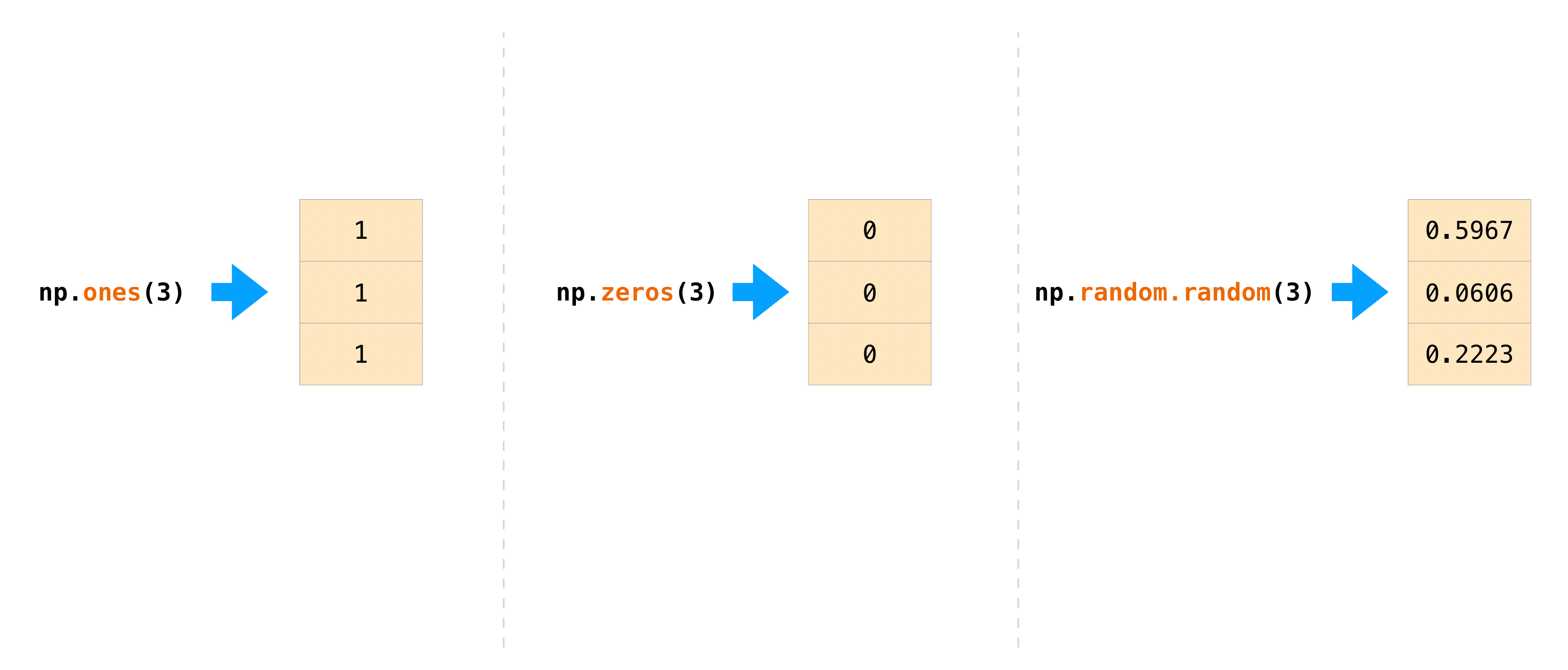
在許多情況下,我們希望 NumPy 初始化陣列的值。NumPy 提供了諸如 ones() 和 zeros() 之類的函式,以及用於隨機數字產生的 random.Generator 類別。您只需要傳入您想要它產生的元素數量
>>> np.ones(3)
array([1., 1., 1.])
>>> np.zeros(3)
array([0., 0., 0.])
>>> rng = np.random.default_rng() # the simplest way to generate random numbers
>>> rng.random(3)
array([0.63696169, 0.26978671, 0.04097352])
如果您給它們一個描述矩陣維度的元組,您也可以使用 ones()、zeros() 和 random() 來建立二維陣列
>>> np.ones((3, 2))
array([[1., 1.],
[1., 1.],
[1., 1.]])
>>> np.zeros((3, 2))
array([[0., 0.],
[0., 0.],
[0., 0.]])
>>> rng.random((3, 2))
array([[0.01652764, 0.81327024],
[0.91275558, 0.60663578],
[0.72949656, 0.54362499]]) # may vary
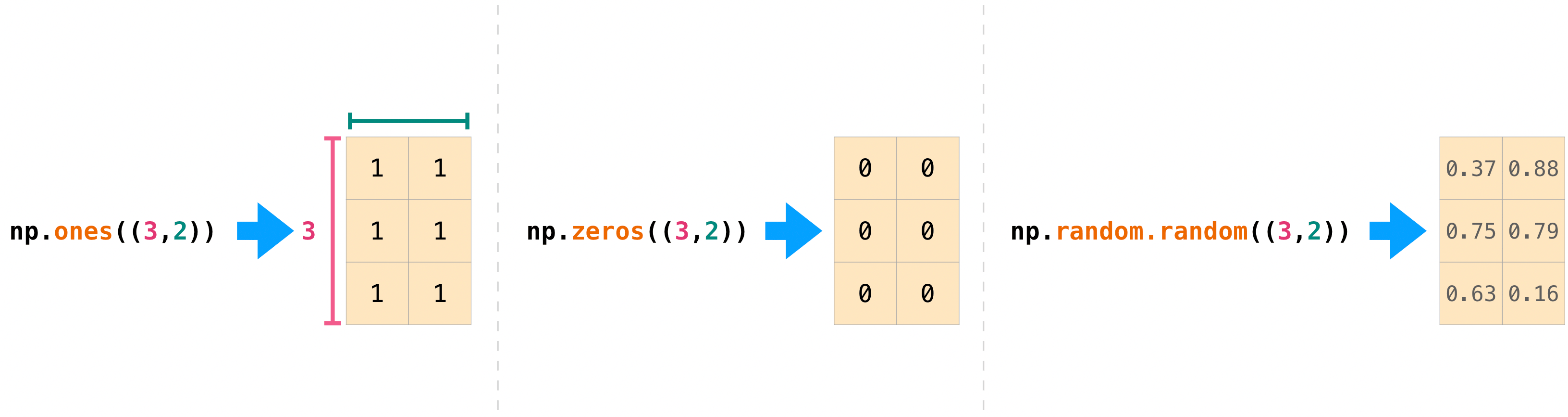
在此處閱讀更多關於建立填充 0、1、其他值或未初始化的陣列的資訊:陣列建立常式。
產生隨機數字#
隨機數字產生的使用是許多數值和機器學習演算法配置和評估的重要組成部分。無論您需要隨機初始化人工神經網路中的權重、將資料分割成隨機集,還是隨機混洗資料集,能夠產生隨機數字(實際上是可重複的偽隨機數字)都是必不可少的。
使用 Generator.integers,您可以產生從 low(請記住 NumPy 中這是包含性的)到 high(排他性)的隨機整數。您可以設定 endpoint=True 使 high 數字具有包含性。
您可以使用以下方式產生介於 0 到 4 之間的 2 x 4 隨機整數陣列
>>> rng.integers(5, size=(2, 4))
array([[2, 1, 1, 0],
[0, 0, 0, 4]]) # may vary
如何取得唯一項目和計數#
本節涵蓋 np.unique()
您可以使用 np.unique 輕鬆找到陣列中的唯一元素。
例如,如果您從這個陣列開始
>>> a = np.array([11, 11, 12, 13, 14, 15, 16, 17, 12, 13, 11, 14, 18, 19, 20])
您可以使用 np.unique 來印出陣列中的唯一值
>>> unique_values = np.unique(a)
>>> print(unique_values)
[11 12 13 14 15 16 17 18 19 20]
若要取得 NumPy 陣列中唯一值的索引(陣列中唯一值的首個索引位置的陣列),只需在 np.unique() 中傳遞 return_index 參數以及您的陣列。
>>> unique_values, indices_list = np.unique(a, return_index=True)
>>> print(indices_list)
[ 0 2 3 4 5 6 7 12 13 14]
您可以將 return_counts 參數與您的陣列一起傳遞到 np.unique() 中,以取得 NumPy 陣列中唯一值的頻率計數。
>>> unique_values, occurrence_count = np.unique(a, return_counts=True)
>>> print(occurrence_count)
[3 2 2 2 1 1 1 1 1 1]
這也適用於 2D 陣列!如果您從這個陣列開始
>>> a_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [1, 2, 3, 4]])
您可以使用以下方式找到唯一值
>>> unique_values = np.unique(a_2d)
>>> print(unique_values)
[ 1 2 3 4 5 6 7 8 9 10 11 12]
如果未傳遞 axis 參數,您的 2D 陣列將會被展平。
如果您想取得唯一的列或行,請務必傳遞 axis 參數。若要尋找唯一的列,請指定 axis=0;若要尋找唯一的行,請指定 axis=1。
>>> unique_rows = np.unique(a_2d, axis=0)
>>> print(unique_rows)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
若要取得唯一的列、索引位置和出現次數,您可以使用
>>> unique_rows, indices, occurrence_count = np.unique(
... a_2d, axis=0, return_counts=True, return_index=True)
>>> print(unique_rows)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(indices)
[0 1 2]
>>> print(occurrence_count)
[2 1 1]
若要深入了解如何在陣列中尋找唯一元素,請參閱 unique。
轉置和重塑矩陣#
本節涵蓋 arr.reshape()、arr.transpose()、arr.T
轉置矩陣是很常見的需求。NumPy 陣列具有屬性 T,可讓您轉置矩陣。
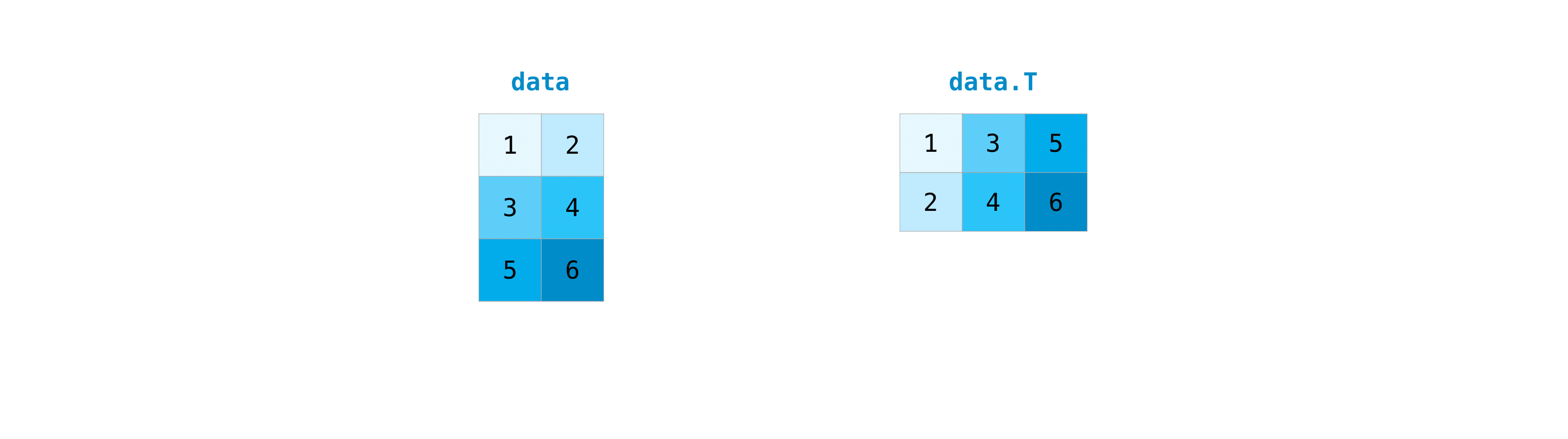
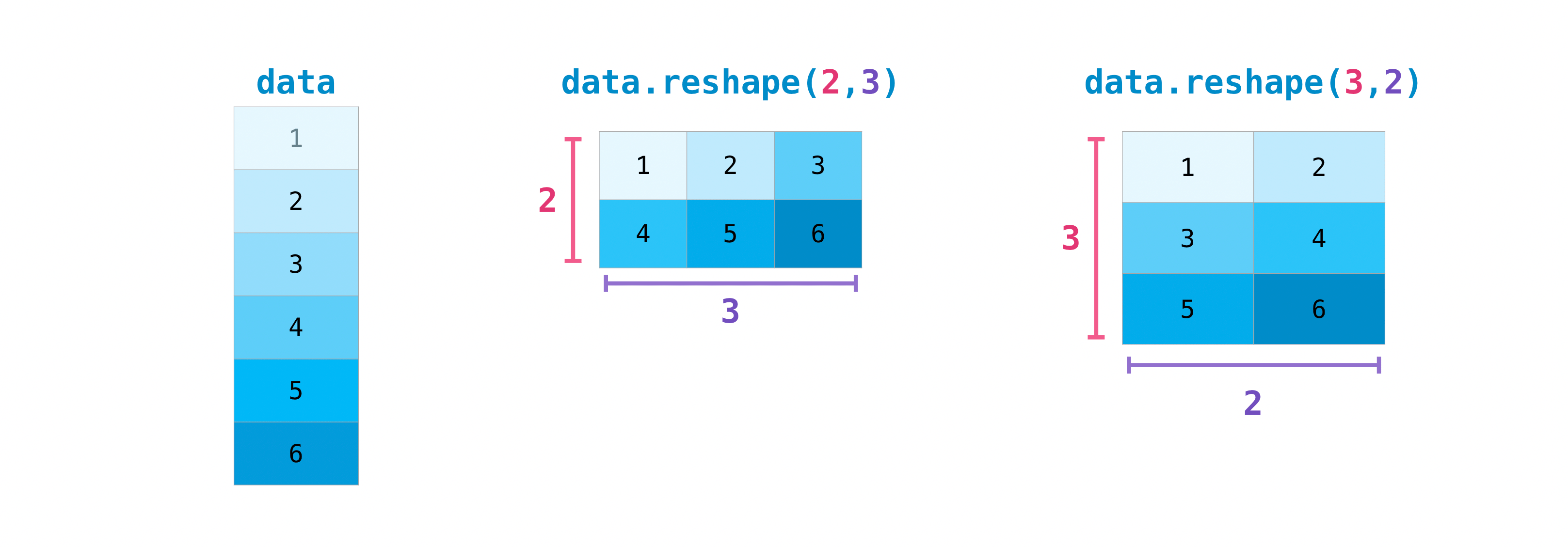
您可能也需要切換矩陣的維度。例如,當您的模型預期的輸入形狀與資料集不同時,可能會發生這種情況。這時 reshape 方法就很有用。您只需傳入您想要的矩陣新維度即可。
>>> data.reshape(2, 3)
array([[1, 2, 3],
[4, 5, 6]])
>>> data.reshape(3, 2)
array([[1, 2],
[3, 4],
[5, 6]])
您也可以使用 .transpose() 根據您指定的值來反轉或更改陣列的軸。
如果您從這個陣列開始
>>> arr = np.arange(6).reshape((2, 3))
>>> arr
array([[0, 1, 2],
[3, 4, 5]])
您可以使用 arr.transpose() 來轉置您的陣列。
>>> arr.transpose()
array([[0, 3],
[1, 4],
[2, 5]])
您也可以使用 arr.T
>>> arr.T
array([[0, 3],
[1, 4],
[2, 5]])
如何反轉陣列#
本節涵蓋 np.flip()
NumPy 的 np.flip() 函數可讓您沿著軸翻轉或反轉陣列的內容。使用 np.flip() 時,請指定您要反轉的陣列和軸。如果您未指定軸,NumPy 將沿著輸入陣列的所有軸反轉內容。
反轉 1D 陣列
如果您從像這樣的一維陣列開始
>>> arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
您可以使用以下方式反轉它
>>> reversed_arr = np.flip(arr)
如果您想印出反轉後的陣列,您可以執行
>>> print('Reversed Array: ', reversed_arr)
Reversed Array: [8 7 6 5 4 3 2 1]
反轉 2D 陣列
二維陣列的運作方式大致相同。
如果您從這個陣列開始
>>> arr_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
您可以使用以下方式反轉所有列和所有行的內容
>>> reversed_arr = np.flip(arr_2d)
>>> print(reversed_arr)
[[12 11 10 9]
[ 8 7 6 5]
[ 4 3 2 1]]
您可以使用以下方式輕鬆地僅反轉列
>>> reversed_arr_rows = np.flip(arr_2d, axis=0)
>>> print(reversed_arr_rows)
[[ 9 10 11 12]
[ 5 6 7 8]
[ 1 2 3 4]]
或僅使用以下方式反轉行
>>> reversed_arr_columns = np.flip(arr_2d, axis=1)
>>> print(reversed_arr_columns)
[[ 4 3 2 1]
[ 8 7 6 5]
[12 11 10 9]]
您也可以僅反轉一列或一行的內容。例如,您可以反轉索引位置 1(第二列)的列內容
>>> arr_2d[1] = np.flip(arr_2d[1])
>>> print(arr_2d)
[[ 1 2 3 4]
[ 8 7 6 5]
[ 9 10 11 12]]
您也可以反轉索引位置 1(第二行)的行內容
>>> arr_2d[:,1] = np.flip(arr_2d[:,1])
>>> print(arr_2d)
[[ 1 10 3 4]
[ 8 7 6 5]
[ 9 2 11 12]]
在 flip 閱讀更多關於反轉陣列的資訊。
重塑和展平多維陣列#
本節涵蓋 .flatten()、ravel()
有兩種常見的方法可以展平陣列:.flatten() 和 .ravel()。兩者之間的主要區別在於,使用 ravel() 建立的新陣列實際上是對父陣列的參考(即「視圖」)。這表示對新陣列的任何變更也會影響父陣列。ravel 因為不建立副本,所以它在記憶體方面更有效率。
如果您從這個陣列開始
>>> x = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
您可以使用 flatten 將陣列展平成一維陣列。
>>> x.flatten()
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
當您使用 flatten 時,對新陣列的變更不會變更父陣列。
例如
>>> a1 = x.flatten()
>>> a1[0] = 99
>>> print(x) # Original array
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(a1) # New array
[99 2 3 4 5 6 7 8 9 10 11 12]
但是當您使用 ravel 時,您對新陣列所做的變更將會影響父陣列。
例如
>>> a2 = x.ravel()
>>> a2[0] = 98
>>> print(x) # Original array
[[98 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(a2) # New array
[98 2 3 4 5 6 7 8 9 10 11 12]
在 ndarray.flatten 閱讀更多關於 flatten 的資訊,並在 ravel 閱讀更多關於 ravel 的資訊。
如何存取文件字串以取得更多資訊#
本節涵蓋 help()、?、??
就資料科學生態系統而言,Python 和 NumPy 的建構都以使用者為中心。其中一個最佳範例是內建的文件存取方式。每個物件都包含對字串的參考,稱為文件字串。在大多數情況下,此文件字串包含物件的快速簡潔摘要以及如何使用它。Python 有一個內建的 help() 函數,可以協助您存取此資訊。這表示幾乎任何時候您需要更多資訊,都可以使用 help() 快速找到您需要的資訊。
例如
>>> help(max)
Help on built-in function max in module builtins:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
由於存取額外資訊非常有用,IPython 使用 ? 字元作為存取此文件以及其他相關資訊的速記方式。IPython 是用於多種語言互動式運算的命令 shell。您可以在此處找到更多關於 IPython 的資訊。
例如
In [0]: max?
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
Type: builtin_function_or_method
您甚至可以將此表示法用於物件方法和物件本身。
假設您建立此陣列
>>> a = np.array([1, 2, 3, 4, 5, 6])
然後您可以取得許多有用的資訊(首先是關於 a 本身的詳細資訊,然後是 ndarray 的文件字串,a 是 ndarray 的實例)
In [1]: a?
Type: ndarray
String form: [1 2 3 4 5 6]
Length: 6
File: ~/anaconda3/lib/python3.9/site-packages/numpy/__init__.py
Docstring: <no docstring>
Class docstring:
ndarray(shape, dtype=float, buffer=None, offset=0,
strides=None, order=None)
An array object represents a multidimensional, homogeneous array
of fixed-size items. An associated data-type object describes the
format of each element in the array (its byte-order, how many bytes it
occupies in memory, whether it is an integer, a floating point number,
or something else, etc.)
Arrays should be constructed using `array`, `zeros` or `empty` (refer
to the See Also section below). The parameters given here refer to
a low-level method (`ndarray(...)`) for instantiating an array.
For more information, refer to the `numpy` module and examine the
methods and attributes of an array.
Parameters
----------
(for the __new__ method; see Notes below)
shape : tuple of ints
Shape of created array.
...
這也適用於您建立的函數和其他物件。只需記住使用字串文字(""" """ 或 ''' ''' 包圍您的文件)在您的函數中包含文件字串。
例如,如果您建立此函數
>>> def double(a):
... '''Return a * 2'''
... return a * 2
您可以取得關於函數的資訊
In [2]: double?
Signature: double(a)
Docstring: Return a * 2
File: ~/Desktop/<ipython-input-23-b5adf20be596>
Type: function
您可以透過閱讀您感興趣的物件的原始程式碼來達到另一個資訊層次。使用雙問號 (??) 可讓您存取原始程式碼。
例如
In [3]: double??
Signature: double(a)
Source:
def double(a):
'''Return a * 2'''
return a * 2
File: ~/Desktop/<ipython-input-23-b5adf20be596>
Type: function
如果所討論的物件是以 Python 以外的語言編譯的,則使用 ?? 將傳回與 ? 相同的資訊。您會在許多內建物件和類型中找到這種情況,例如
In [4]: len?
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
和
In [5]: len??
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
具有相同的輸出,因為它們是以 Python 以外的程式語言編譯的。
使用數學公式#
在陣列上運作的數學公式易於實作,這是 NumPy 在科學 Python 社群中如此廣泛使用的原因之一。
例如,這是均方誤差公式(用於處理迴歸的監督式機器學習模型中使用的核心公式)
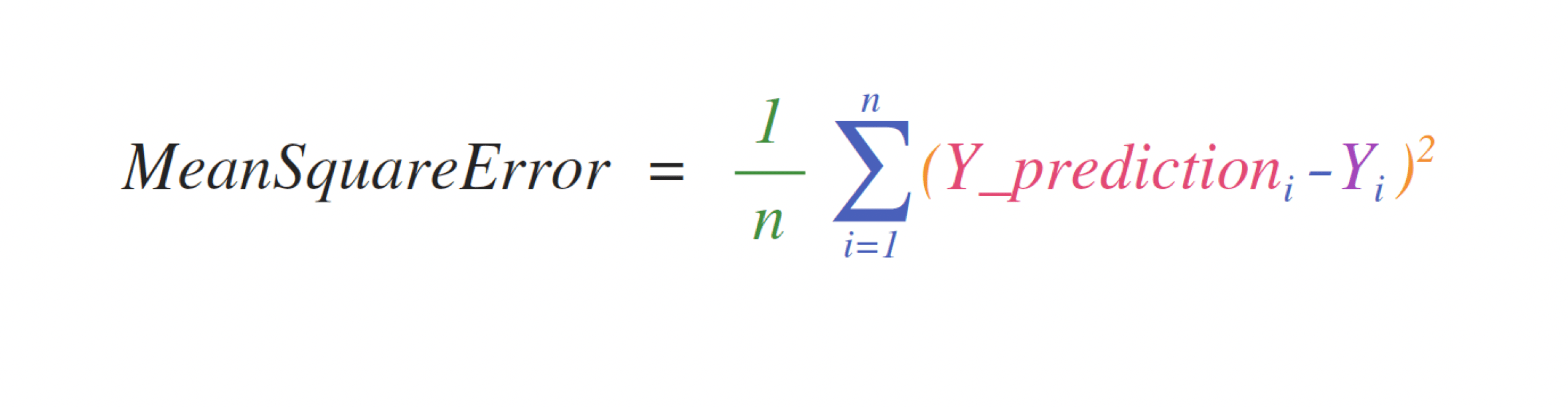
在 NumPy 中實作此公式既簡單又直接
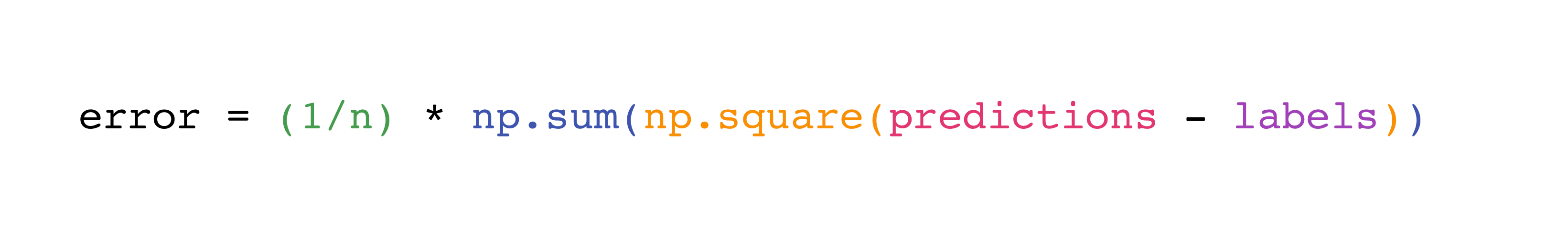
這之所以能如此順利運作的原因是 predictions 和 labels 可以包含一個或一千個值。它們只需要大小相同即可。
您可以這樣視覺化它

在此範例中,預測和標籤向量都包含三個值,表示 n 的值為三。在我們執行減法後,向量中的值會平方。然後 NumPy 會加總這些值,而您的結果就是該預測的誤差值以及模型品質的分數。

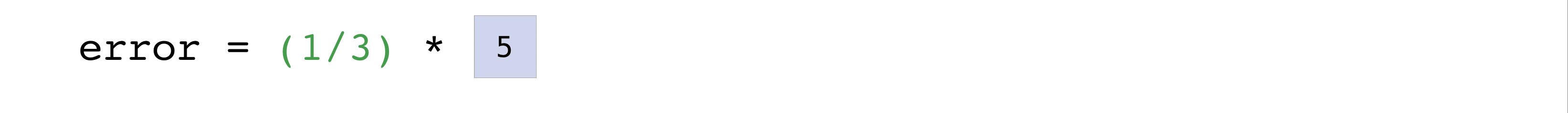
如何儲存和載入 NumPy 物件#
本節涵蓋 np.save、np.savez、np.savetxt、np.load、np.loadtxt
在某些時候,您會想要將陣列儲存到磁碟並載入回來,而無需重新執行程式碼。幸運的是,有幾種方法可以使用 NumPy 儲存和載入物件。ndarray 物件可以使用 loadtxt 和 savetxt 函數(處理一般文字檔)、load 和 save 函數(處理副檔名為 .npy 的 NumPy 二進位檔)以及 savez 函數(處理副檔名為 .npz 的 NumPy 檔)儲存到磁碟檔案並從中載入。
.npy 和 .npz 檔案儲存資料、形狀、dtype 和其他重建 ndarray 所需的資訊,以便即使檔案位於具有不同架構的另一部機器上,也能正確擷取陣列。
如果您想要儲存單一 ndarray 物件,請使用 np.save 將其儲存為 .npy 檔案。如果您想要在單一檔案中儲存多個 ndarray 物件,請使用 np.savez 將其儲存為 .npz 檔案。您也可以使用 savez_compressed 以壓縮的 npz 格式將多個陣列儲存到單一檔案中。
使用 np.save() 儲存和載入陣列很容易。只需確保指定您要儲存的陣列和檔案名稱。例如,如果您建立此陣列
>>> a = np.array([1, 2, 3, 4, 5, 6])
您可以使用以下方式將其儲存為 “filename.npy”
>>> np.save('filename', a)
您可以使用 np.load() 來重建您的陣列。
>>> b = np.load('filename.npy')
如果您想檢查您的陣列,可以執行
>>> print(b)
[1 2 3 4 5 6]
您可以使用 np.savetxt 將 NumPy 陣列儲存為純文字檔,例如 .csv 或 .txt 檔案。
例如,如果您建立此陣列
>>> csv_arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
您可以使用以下方式輕鬆地將其儲存為名為 “new_file.csv” 的 .csv 檔案
>>> np.savetxt('new_file.csv', csv_arr)
您可以使用 loadtxt() 快速輕鬆地載入您儲存的文字檔
>>> np.loadtxt('new_file.csv')
array([1., 2., 3., 4., 5., 6., 7., 8.])
savetxt() 和 loadtxt() 函數接受其他選用參數,例如 header、footer 和 delimiter。雖然文字檔更易於共享,但 .npy 和 .npz 檔案更小且讀取速度更快。如果您需要更複雜地處理文字檔(例如,如果您需要處理包含遺失值的行),您會想要使用 genfromtxt 函數。
使用 savetxt,您可以指定標頭、頁尾、註解等等。
在此處深入了解 輸入和輸出常式。
匯入和匯出 CSV#
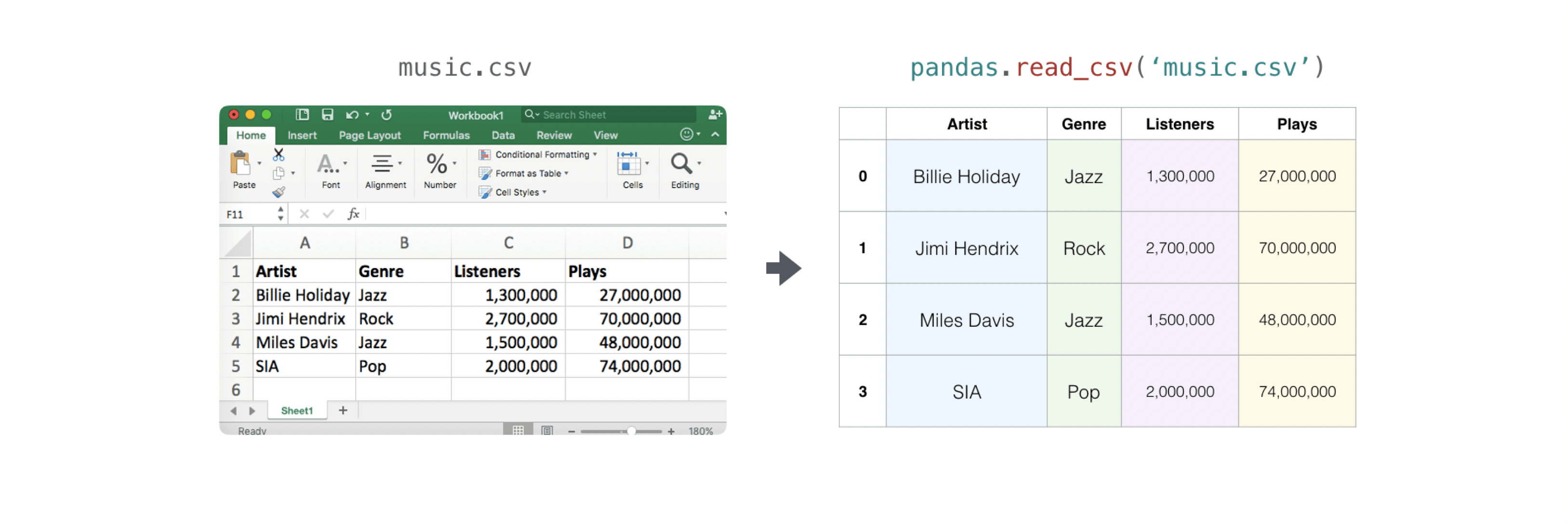
讀取包含現有資訊的 CSV 很簡單。執行此操作的最佳且最簡單方法是使用 Pandas。
>>> import pandas as pd
>>> # If all of your columns are the same type:
>>> x = pd.read_csv('music.csv', header=0).values
>>> print(x)
[['Billie Holiday' 'Jazz' 1300000 27000000]
['Jimmie Hendrix' 'Rock' 2700000 70000000]
['Miles Davis' 'Jazz' 1500000 48000000]
['SIA' 'Pop' 2000000 74000000]]
>>> # You can also simply select the columns you need:
>>> x = pd.read_csv('music.csv', usecols=['Artist', 'Plays']).values
>>> print(x)
[['Billie Holiday' 27000000]
['Jimmie Hendrix' 70000000]
['Miles Davis' 48000000]
['SIA' 74000000]]
使用 Pandas 匯出您的陣列也很簡單。如果您是 NumPy 的新手,您可能想要從陣列中的值建立 Pandas 資料框架,然後使用 Pandas 將資料框架寫入 CSV 檔案。
如果您建立了這個陣列 “a”
>>> a = np.array([[-2.58289208, 0.43014843, -1.24082018, 1.59572603],
... [ 0.99027828, 1.17150989, 0.94125714, -0.14692469],
... [ 0.76989341, 0.81299683, -0.95068423, 0.11769564],
... [ 0.20484034, 0.34784527, 1.96979195, 0.51992837]])
您可以建立 Pandas 資料框架
>>> df = pd.DataFrame(a)
>>> print(df)
0 1 2 3
0 -2.582892 0.430148 -1.240820 1.595726
1 0.990278 1.171510 0.941257 -0.146925
2 0.769893 0.812997 -0.950684 0.117696
3 0.204840 0.347845 1.969792 0.519928
您可以使用以下方式輕鬆儲存您的資料框架
>>> df.to_csv('pd.csv')
並使用以下方式讀取您的 CSV
>>> data = pd.read_csv('pd.csv')

您也可以使用 NumPy savetxt 方法儲存您的陣列。
>>> np.savetxt('np.csv', a, fmt='%.2f', delimiter=',', header='1, 2, 3, 4')
如果您使用命令列,您可以隨時使用如下命令讀取您儲存的 CSV
$ cat np.csv
# 1, 2, 3, 4
-2.58,0.43,-1.24,1.60
0.99,1.17,0.94,-0.15
0.77,0.81,-0.95,0.12
0.20,0.35,1.97,0.52
或者您可以隨時使用文字編輯器開啟檔案!
如果您有興趣深入了解 Pandas,請查看 官方 Pandas 文件。了解如何使用 官方 Pandas 安裝資訊 安裝 Pandas。
使用 Matplotlib 繪製陣列#
如果您需要為您的值產生繪圖,使用 Matplotlib 非常簡單。
例如,您可能有一個像這樣的陣列
>>> a = np.array([2, 1, 5, 7, 4, 6, 8, 14, 10, 9, 18, 20, 22])
如果您已經安裝了 Matplotlib,您可以使用以下方式匯入它
>>> import matplotlib.pyplot as plt
# If you're using Jupyter Notebook, you may also want to run the following
# line of code to display your code in the notebook:
%matplotlib inline
您只需要執行以下操作即可繪製您的值
>>> plt.plot(a)
# If you are running from a command line, you may need to do this:
# >>> plt.show()
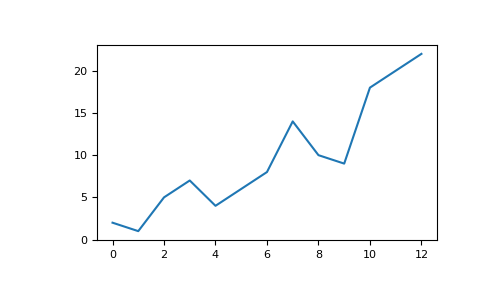
例如,您可以繪製像這樣的一維陣列
>>> x = np.linspace(0, 5, 20)
>>> y = np.linspace(0, 10, 20)
>>> plt.plot(x, y, 'purple') # line
>>> plt.plot(x, y, 'o') # dots
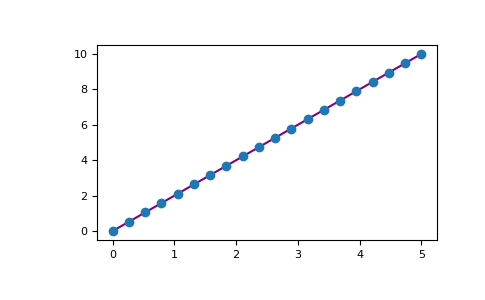
使用 Matplotlib,您可以存取大量的視覺化選項。
>>> fig = plt.figure()
>>> ax = fig.add_subplot(projection='3d')
>>> X = np.arange(-5, 5, 0.15)
>>> Y = np.arange(-5, 5, 0.15)
>>> X, Y = np.meshgrid(X, Y)
>>> R = np.sqrt(X**2 + Y**2)
>>> Z = np.sin(R)
>>> ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='viridis')

若要閱讀更多關於 Matplotlib 及其功能的資訊,請查看 官方文件。如需關於安裝 Matplotlib 的指示,請參閱官方 安裝章節。
圖片來源:Jay Alammar https://jalammar.github.io/