

純量#
Python 僅定義特定資料類別的一種型別(只有一種整數型別、一種浮點數型別等)。這在不需要關心資料在電腦中所有表示方式的應用程式中可能很方便。然而,對於科學計算,通常需要更多控制。
在 NumPy 中,有 24 種新的基本 Python 型別來描述不同類型的純量。這些型別描述符主要基於 CPython 編寫時使用的 C 語言中可用的型別,以及幾種與 Python 型別相容的額外型別。
陣列純量具有與 ndarrays 相同的屬性和方法。[1] 這允許人們將陣列的項目部分地視為與陣列相同的地位,從而消除混合純量和陣列運算時產生的粗糙邊緣。
陣列純量存在於資料類型層次結構中(請參閱下圖)。可以使用層次結構偵測它們:例如,如果 val 是陣列純量物件,則 isinstance(val, np.generic) 將傳回 True。或者,可以使用資料類型層次結構的其他成員來判斷存在的陣列純量的種類。因此,例如,如果 val 是複數值型別,則 isinstance(val, np.complexfloating) 將傳回 True,而如果 val 是彈性項目大小陣列型別(str_、bytes_、void)之一,則 isinstance(val, np.flexible) 將傳回 true。
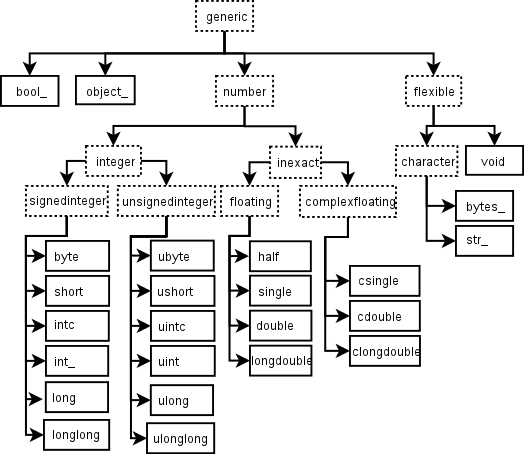
圖: 表示陣列資料類型之型別物件的層次結構。未顯示用於索引的兩種整數型別 intp 和 uintp(與 NumPy 2 以來的預設整數相同)。#
內建純量型別#
內建純量型別如下所示。類似 C 的名稱與字元代碼相關聯,字元代碼顯示在其描述中。但是,不建議使用字元代碼。
某些純量型別本質上等同於基本 Python 型別,因此也從它們以及通用陣列純量型別繼承
陣列純量型別 |
相關的 Python 型別 |
繼承? |
|---|---|---|
僅限 Python 2 |
||
是 |
||
是 |
||
是 |
||
是 |
||
否 |
||
否 |
||
否 |
bool_ 資料類型與 Python bool 非常相似,但不從它繼承,因為 Python 的 bool 不允許從它繼承,並且在 C 層級,實際 bool 資料的大小與 Python 布林純量的大小不同。
提示
NumPy 中的預設資料類型為 double。
- class numpy.generic[原始碼]#
numpy 純量型別的基底類別。
大多數(全部?)numpy 純量型別都由此類別衍生而來。為了保持一致性,它公開了與
ndarray相同的 API,儘管許多後續屬性是「唯讀」的,或完全不相關。強烈建議使用者從這個類別衍生自訂純量型別。
整數型別#
注意
numpy 整數型別反映 C 整數的行為,因此可能會受到溢位錯誤的影響。
帶正負號的整數型別#
- class numpy.byte[原始碼]#
帶正負號的整數型別,與 C
char相容。- 字元代碼:
'b'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.int8:8 位元帶正負號的整數(-128到127)。
- class numpy.short[原始碼]#
帶正負號的整數型別,與 C
short相容。- 字元代碼:
'h'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.int16:16 位元帶正負號的整數(-32_768到32_767)。
- class numpy.intc[原始碼]#
帶正負號的整數型別,與 C
int相容。- 字元代碼:
'i'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.int32:32 位元帶正負號的整數(-2_147_483_648到2_147_483_647)。
- class numpy.int_[原始碼]#
預設帶正負號的整數型別,在 64 位元系統上為 64 位元,在 32 位元系統上為 32 位元。
- 字元代碼:
'l'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.int64:64 位元帶正負號的整數(-9_223_372_036_854_775_808到9_223_372_036_854_775_807)。- 此平台上的別名 (Linux x86_64):
numpy.intp:帶正負號的整數,大小足以容納指標,與 Cintptr_t相容。
不帶正負號的整數型別#
- class numpy.ubyte[原始碼]#
不帶正負號的整數型別,與 C
unsigned char相容。- 字元代碼:
'B'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.uint8:8 位元不帶正負號的整數(0到255)。
- class numpy.ushort[原始碼]#
不帶正負號的整數型別,與 C
unsigned short相容。- 字元代碼:
'H'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.uint16:16 位元不帶正負號的整數(0到65_535)。
- class numpy.uintc[原始碼]#
不帶正負號的整數型別,與 C
unsigned int相容。- 字元代碼:
'I'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.uint32:32 位元不帶正負號的整數(0到4_294_967_295)。
- class numpy.uint[原始碼]#
不帶正負號的帶正負號的整數型別,在 64 位元系統上為 64 位元,在 32 位元系統上為 32 位元。
- 字元代碼:
'L'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.uint64:64 位元不帶正負號的整數(0到18_446_744_073_709_551_615)。- 此平台上的別名 (Linux x86_64):
numpy.uintp:不帶正負號的整數,大小足以容納指標,與 Cuintptr_t相容。
不精確型別#
注意
不精確的純量會使用最少的十進位數字印出,這些數字足以透過明智的四捨五入將其值與相同資料類型的其他值區分開來。請參閱 format_float_positional 和 format_float_scientific 的 unique 參數。
這表示具有相等二進位值但資料類型精度不同的變數可能會顯示不同
>>> import numpy as np>>> f16 = np.float16("0.1") >>> f32 = np.float32(f16) >>> f64 = np.float64(f32) >>> f16 == f32 == f64 True >>> f16, f32, f64 (0.1, 0.099975586, 0.0999755859375)請注意,這些浮點數都沒有精確值 \(\frac{1}{10}\);
f16印出為0.1,因為它盡可能接近該值,而其他型別則不然,因為它們具有更高的精度,因此具有更接近的值。相反地,儘管浮點純量的精度不同,但近似於相同十進位值的浮點純量即使印出相同也可能比較不相等
>>> f16 = np.float16("0.1") >>> f32 = np.float32("0.1") >>> f64 = np.float64("0.1") >>> f16 == f32 == f64 False >>> f16, f32, f64 (0.1, 0.1, 0.1)
浮點型別#
- class numpy.half[原始碼]#
半精度浮點數型別。
- 字元代碼:
'e'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.float16:16 位元精度浮點數型別:符號位元、5 位元指數、10 位元尾數。
- class numpy.single[原始碼]#
單精度浮點數型別,與 C
float相容。- 字元代碼:
'f'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.float32:32 位元精度浮點數型別:符號位元、8 位元指數、23 位元尾數。
- class numpy.double(x=0, /)[原始碼]#
雙精度浮點數型別,與 Python
float和 Cdouble相容。- 字元代碼:
'd'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.float64:64 位元精度浮點數型別:符號位元、11 位元指數、52 位元尾數。
- class numpy.longdouble[原始碼]#
延伸精度浮點數型別,與 C
long double相容,但不一定與 IEEE 754 四倍精度相容。- 字元代碼:
'g'- 此平台上的別名 (Linux x86_64):
numpy.float128:128 位元延伸精度浮點數型別。
複數浮點型別#
- class numpy.csingle[原始碼]#
由兩個單精度浮點數組成的複數型別。
- 字元代碼:
'F'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.complex64:由 2 個 32 位元精度浮點數組成的複數型別。
- class numpy.cdouble(real=0, imag=0)[原始碼]#
由兩個雙精度浮點數組成的複數型別,與 Python
complex相容。- 字元代碼:
'D'- 標準名稱:
- 此平台上的別名 (Linux x86_64):
numpy.complex128:由 2 個 64 位元精度浮點數組成的複數型別。
- class numpy.clongdouble[原始碼]#
由兩個延伸精度浮點數組成的複數型別。
- 字元代碼:
'G'- 此平台上的別名 (Linux x86_64):
numpy.complex256:由 2 個 128 位元延伸精度浮點數組成的複數型別。
其他型別#
- class numpy.datetime64[原始碼]#
如果從 64 位元整數建立,它表示與
1970-01-01T00:00:00的偏移量。如果從字串建立,則字串可以是 ISO 8601 日期或日期時間格式。當剖析字串以建立日期時間物件時,如果字串包含尾隨時區(「Z」或時區偏移量),則會捨棄時區並發出使用者警告。
Datetime64 物件應被視為 UTC,因此偏移量為 +0000。
>>> np.datetime64(10, 'Y') np.datetime64('1980') >>> np.datetime64('1980', 'Y') np.datetime64('1980') >>> np.datetime64(10, 'D') np.datetime64('1970-01-11')
有關更多資訊,請參閱日期時間和時間差。
- 字元代碼:
'M'
注意
物件陣列(即,dtype 為 object_ 的陣列)中實際儲存的資料是對 Python 物件的參照,而不是物件本身。因此,物件陣列的行為更像常見的 Python lists,因為它們的內容不一定需要是相同的 Python 類型。
物件類型也很特別,因為包含 object_ 項目的陣列在項目存取時不會傳回 object_ 物件,而是傳回陣列項目參照的實際物件。
以下資料類型是彈性的:它們沒有預定義的大小,且它們描述的資料在不同的陣列中可以有不同的長度。(在字元代碼中,# 是一個整數,表示資料類型由多少個元素組成。)
- class numpy.flexible[source]#
所有沒有預定義長度的純量類型的抽象基底類別。這些類型的實際大小取決於特定的
numpy.dtype實例化。
- class numpy.str_[source]#
Unicode 字串。
此類型會去除尾隨的空碼位。
>>> s = np.str_("abc\x00") >>> s 'abc'
與內建的
str不同,此類型支援 緩衝區協定,將其內容公開為 UCS4>>> m = memoryview(np.str_("abc")) >>> m.format '3w' >>> m.tobytes() b'a\x00\x00\x00b\x00\x00\x00c\x00\x00\x00'
- 字元代碼:
'U'
- class numpy.void(length_or_data, /, dtype=None)[source]#
建立新的結構化或非結構化 void 純量。
- 參數:
註解
由於歷史原因,且 void 純量可以表示任意位元組資料和結構化 dtype,因此 void 建構子有三種呼叫慣例
np.void(5)建立一個dtype="V5"純量,並填充五個\0位元組。5 可以是 Python 或 NumPy 整數。np.void(b"bytes-like")從位元組字串建立 void 純量。dtype itemsize 將與位元組字串長度相符,此處為"V10"。當傳遞
dtype=時,呼叫大致與陣列建立相同。但是,會傳回 void 純量而不是陣列。
請參閱範例,其中顯示了所有三種不同的慣例。
範例
>>> np.void(5) np.void(b'\x00\x00\x00\x00\x00') >>> np.void(b'abcd') np.void(b'\x61\x62\x63\x64') >>> np.void((3.2, b'eggs'), dtype="d,S5") np.void((3.2, b'eggs'), dtype=[('f0', '<f8'), ('f1', 'S5')]) >>> np.void(3, dtype=[('x', np.int8), ('y', np.int8)]) np.void((3, 3), dtype=[('x', 'i1'), ('y', 'i1')])
- 字元代碼:
'V'
已調整大小的別名#
除了它們(大部分)C 衍生的名稱外,整數、浮點數和複數資料類型也可以使用位元寬度慣例,以便始終可以確保正確大小的陣列。還提供指向足夠大以容納 C 指標的整數類型的兩個別名(numpy.intp 和 numpy.uintp)。
- numpy.int8[source]#
- numpy.int16#
- numpy.int32#
- numpy.int64#
帶符號整數類型的別名(
numpy.byte、numpy.short、numpy.intc、numpy.int_、numpy.long和numpy.longlong之一),具有指定的位元數。分別與 C99
int8_t、int16_t、int32_t和int64_t相容。
- numpy.uint8[source]#
- numpy.uint16#
- numpy.uint32#
- numpy.uint64#
無符號整數類型的別名(
numpy.ubyte、numpy.ushort、numpy.uintc、numpy.uint、numpy.ulong和numpy.ulonglong之一),具有指定的位元數。分別與 C99
uint8_t、uint16_t、uint32_t和uint64_t相容。
- numpy.intp[source]#
用作預設整數和索引的帶符號整數類型(
numpy.byte、numpy.short、numpy.intc、numpy.int_、numpy.long和numpy.longlong之一)的別名。與 C
Py_ssize_t相容。- 字元代碼:
'n'
在 2.0 版本中變更:在 NumPy 2 之前,它與指標的大小相同。實際上,這幾乎總是相同的,但字元代碼
'p'對應於 Cintptr_t。字元代碼'n'在 NumPy 2.0 中新增。
- numpy.uintp[source]#
與
intp大小相同的無符號整數類型的別名。與 C
size_t相容。- 字元代碼:
'N'
在 2.0 版本中變更:在 NumPy 2 之前,它與指標的大小相同。實際上,這幾乎總是相同的,但字元代碼
'P'對應於 Cuintptr_t。字元代碼'N'在 NumPy 2.0 中新增。
- numpy.float96#
- numpy.float128[source]#
numpy.longdouble的別名,以其位元大小命名。這些別名的存在取決於平台。
- numpy.complex192#
- numpy.complex256[source]#
numpy.clongdouble的別名,以其位元大小命名。這些別名的存在取決於平台。
屬性#
陣列純量物件的 array priority 為 NPY_SCALAR_PRIORITY (-1,000,000.0)。它們(尚未)也沒有 ctypes 屬性。否則,它們與陣列共享相同的屬性
旗標的整數值。 |
|
陣列維度的元組。 |
|
每個維度中的位元組步幅元組。 |
|
陣列維度的數量。 |
|
指向資料開始位置的指標。 |
|
gentype 中的元素數量。 |
|
一個元素以位元組為單位的長度。 |
|
與對應陣列屬性相同的純量屬性。 |
|
取得陣列資料描述符。 |
|
純量的實部。 |
|
純量的虛部。 |
|
純量的 1 維視圖。 |
|
與對應陣列屬性相同的純量屬性。 |
|
陣列協定:Python 端 |
|
陣列協定:struct |
|
陣列優先級。 |
|
純量類型的 __array_wrap__ 實作 |
索引#
另請參閱
陣列純量可以像 0 維陣列一樣建立索引:如果 x 是陣列純量,
x[()]傳回陣列純量的副本x[...]傳回 0 維ndarrayx['field-name']傳回欄位 field-name 中的陣列純量。(x 可以有欄位,例如,當它對應於結構化資料類型時。)
方法#
陣列純量與陣列具有完全相同的方法。這些方法的預設行為是在內部將純量轉換為等效的 0 維陣列,並呼叫對應的陣列方法。此外,陣列純量上的數學運算經過定義,使得設定相同的硬體旗標,並用於解釋結果,如同 ufunc 一樣,因此用於 ufunc 的錯誤狀態也延續到陣列純量上的數學運算。
上述規則的例外情況如下
sc.__array__(dtype) 從具有指定 dtype 的純量傳回 0 維陣列 |
|
純量類型的 __array_wrap__ 實作 |
|
與對應陣列屬性相同的純量方法。 |
|
與對應陣列屬性相同的純量方法。 |
|
pickle 的輔助程式。 |
|
與對應陣列屬性相同的純量方法。 |
用於輸入的實用方法
|
傳回 |
定義新類型#
有兩種有效定義新陣列純量類型的方法(除了從內建純量類型組合結構化類型 dtypes 之外):一種方法是簡單地子類別化 ndarray 並覆寫感興趣的方法。這在一定程度上會起作用,但內部某些行為由陣列的資料類型固定。若要完全自訂陣列的資料類型,您需要定義新的資料類型,並將其註冊到 NumPy。此類新類型只能在 C 中定義,使用 NumPy C-API。